3. Development-time threats
Edit page3.0 Development-time threats - Introduction
Category: group of development-time threats
Permalink: https://owaspai.org/go/developmenttime/
This section discusses the AI security threats during the development of the AI system, which includes the engineering environment and the supply chain as attack surfaces.
Background
Data science (data engineering and model engineering - for machine learning often referred to as the training phase) introduces new elements and therefore new attack surfaces into the engineering environment. Data engineering (collecting, storing, and preparing data) is typically a large and important part of machine learning engineering. Together with model engineering, it requires appropriate security to protect against data leaks, data poisoning, leaks of intellectual property, and supply chain attacks (see further below). In addition, data quality assurance can help reduce risks of intended and unintended data issues.
Particularities
- Particularity 1: the data in the AI development environment is real data that is typically sensitive, because it is needed to train the model and that obviously needs to happen on real data, instead of fake data that you typically see in standard development environment situations (e.g., for testing). Therefore, data protection activities need to be extended from the live system to the development environment.
- Particularity 2: elements in the AI development environment (data, code, configuration & parameters) require extra protection as they are prone to attacks to manipulate model behaviour (called poisoning)
- Particularity 3: source code, configuration, and parameters are typically critical intellectual property in AI
- Particularity 4: the supply chain for AI systems introduces new elements: data, model, AI components and model hosting.
- Particularity 5: external software components may run within the engineering environments, for example to train models, introducing a new threat of malicious components gaining access to assets in that environment (e.g., to poison training data)
- Particularity 6: software components for AI systems can also run in the development environment instead of in production (for example data-processing libraries, feature-engineering tools, or, or even the training framework itself). This increases the attack surface because malicious development components could gain access to training data or model parameters.
- Particularity 7: Model development can be done in a collaborative way across trust boundaries, such as federated learning, merging parameter-efficient fine-tuning (PEFT) modules, and using model conversion services. These collaborations can mitigate some risks by for example spreading training data, but they also extend the attack surface and as such increase threats such as data poisoning.
ISO/IEC 42001 B.7.2 briefly mentions development-time data security risks.
Controls for development-time protection
- See General controls
- Specifically for development-time threats - all discussed below:
- #DEV SECURITY to protect the development environment
- #SEGREGATE DATA to create parts of the development environment with extra protection
- #CONF COMPUTE for denying access to where sensitive data is processed
- #FEDERATED LEARNING to decreases the risk of all data leaking and as a side-effect: increase the risk of some data leaking
- #SUPPLY CHAIN MANAGE especially to control where data and models come from
#DEV SECURITY
Category: development-time information security control
Permalink: https://owaspai.org/go/devsecurity/
Description
Development security: appropriate security of the AI development infrastructure, also taking into account the sensitive information that is typical to AI: training data, test data, model parameters and technical documentation.
Implementation
How: This can be achieved by adding the said assets to the existing security management system. Security involves for example encryption, screening of development personnel, protection of source code/configuration, virus scanning on engineering machines.
Importance: In case the said assets leak, it hurts the confidentiality of intellectual property and/or the confidentiality of train/test data which may contain company secrets, or personal data for example. Also the integrity of this data is important to protect, to prevent data or model poisoning.
Risks external to the development environment
Data and models may have been obtained externally, just like software components. Furthermore, software components often run within the AI development environment, introducing new risks, especially given that sensitive data is present in this environment. For details, see SUPPLYCHAINMANAGE.
Training data is in most cases only present during development-time, but there are exceptions:
- A machine learning model may be continuously trained with data collected at runtime, which puts (part of the) training data in the runtime environment, where it also needs protection - as covered in this control section
- For GenAI, information can be retrieved from a repository to be added to a prompt (augmentation), for example to inform a large language model about the context to take into account for an instruction or question. This principle is called in-context learning. For example OpenCRE-chat uses a repository of requirements from security standards to add to a user question so that the large language model is more informed with background information. In the case of OpenCRE-chat this information is public, but in many cases the application of this so-called Retrieval Augmented Generation (RAG) will have a repository with company secrets or otherwise sensitive data. Organizations can benefit from unlocking their unique data, to be used by themselves, or to be provided as service or product. This is an attractive architecture because the alternative would be to train an LLM or to finetune it, which is expensive and difficult. A RAG approach may suffice. Effectively, this puts the repository data to the same use as training data is used: control the behaviour of the model. Therefore, the security controls that apply to train data, also apply to this run-time repository data. See augmentation data manipulation.
- For GenAI, a special type of data to be added to input is a system prompt: instructions to the model regarding its behaviour. It is also used to augment the input of the model, so it determines the model behaviour and therefore is an asset to protect.
Details on the how: protection strategies:
- Encryption of data at rest
Useful standards include:- ISO 27002 control 5.33 Protection of records. Gap: covers this control fully, with the particularities
- OpenCE on encryption of data at rest
- Technical access control for the data, to limit access following the least privilege principle
Useful standards include: - Operational security to protect stored data
One control to increase development security is to segregate the environment, see SEGREGATEDATA.
Useful standards include:- Many ISO 27002 controls cover operational security. Gap: covers this control fully, with the particularities.
- ISO 27002 control 5.23 Information security for use of cloud services
- ISO 27002 control 5.37 Documented operating procedures
- Many more ISO 27002 controls (See OpenCRE link)
- OpenCRE
- Many ISO 27002 controls cover operational security. Gap: covers this control fully, with the particularities.
- Logging and monitoring to detect suspicious manipulation of data, (e.g., outside office hours)
Useful standards include:- ISO 27002 control 8.16 Monitoring activities. Gap: covers this control fully
- OpenCRE on Detect and respond
- Integrity checking: see section below
Integrity checking
Part of development security is checking the integrity of assets. These assets include train/test/validation data, models/model parameters, source code and binaries.
Integrity checks can be performed at various stages including build, deploy, and supply chain management. The integration of these checks helps mitigate risks associated with tampering: unauthorized modifications and mistakes.
Integrity Checks - Build Stage
During the build stage, it is crucial to validate the integrity of the source code and dependencies to ensure that no unauthorized changes have been introduced. Techniques include:
- Source Code Verification: Implementing code signing and checksums to verify the integrity of the source code. This ensures that the code has not been tampered with.
- Dependency Management: Regularly auditing and updating third-party libraries and dependencies to avoid vulnerabilities. Use tools like Software Composition Analysis (SCA) to automate this process. See #SUPPLY CHAIN MANAGE.
- Automated Testing: Employing continuous integration (CI) pipelines with automated tests to detect issues early in the development cycle. This includes unit tests, integration tests, and security tests.
Example: A software company using CI pipelines can integrate automated security tools to scan for vulnerabilities in the codebase and dependencies, ensuring that only secure and verified code progresses through the pipeline.
Integrity Checks - Deploy Stage
The deployment stage requires careful management to ensure that the AI models and supporting infrastructure are securely deployed and configured. Key practices include:
- Environment Configuration: Ensuring that deployment environments are securely configured and consistent with security policies. This includes the use of Infrastructure as Code (IaC) tools to maintain configuration integrity.
- Secure Deployment Practices: Implementing deployment automation to minimize human error and enforce consistency. Use deployment tools that support rollback capabilities to recover from failed deployments.
- Runtime Integrity Monitoring: Continuously monitoring the deployed environment for integrity violations. Tools like runtime application self-protection (RASP) can provide real-time protection and alert on suspicious activities.
Example: A cloud-based AI service provider can use IaC tools to automate the deployment of secure environments and continuously monitor for configuration drifts or unauthorized changes.
Supply Chain Management
Managing the AI supply chain involves securing the components and processes involved in developing and deploying AI systems. This includes:
- Component Authenticity: Using cryptographic signatures to verify the authenticity and integrity of components received from suppliers. This prevents the introduction of malicious components into the system.
- For more details, see #SUPPLY CHAIN MANAGE
Example: An organization using pre-trained AI models from external vendors can require those vendors to provide cryptographic signatures for model files and detailed security assessments, ensuring the integrity and security of these models before integration.
A significant step forward for provable machine learning model provenance is the cryptographic signing of models, similar in concept to how we secure HTTP traffic using Secure Socket Layer (SSL) or Portable Executable (PE) files with Authenticode. However, there is one key difference: models encompass a number of associated artifacts of varying file formats rather than a single homogeneous file, and so the approach must differ. As mentioned, models comprise code and data but often require additional information able to execute correctly, such as tokenizers, vocab files, configs, and inference code. These are used to initialize the model so it’s ready to accept data and perform its task. To comprehensively verify a model’s integrity, all of these factors must be considered when assessing illicit tampering or manipulation of the model, as any change made to a file that is required for the model to run may introduce a malicious action or degradation of performance to the model. While no standard yet exists to tackle this, there is ongoing work by the OpenSSF Model Signing SIG to define a specification and drive industry adoption. As this is unfolding, there may be interplay with ML-BOM and AI-BOM to be codified into the certificate. Signing and verification will become a major part of the ML ecosystem as it has with many other practices, and guidance will be available following an agreed-upon open-source specification.
The data a model consumes is the most influential part of the MLOps lifecycle and should be treated as such. Data is more often than not sourced from third parties via the internet or gathered on internal data for later training by the model, but can the integrity of the data be assured?
Often, datasets may not just be a collection of text or images but may be comprised of pointers to other pieces of data rather than the data itself. One such dataset is the LAOIN-400m, where pointers to images are stored as URLs - however, data stored at a URL is not permanent and may be subject to manipulation or removal of the content. As such having a level of indirection can introduce integrity issues and leave oneself vulnerable to data poisoning, as was shown by Carlini et al in their paper ‘Poisoning Web-Scale Datasets is practical’. For more information, see the data poisoning section. Verification of dataset entries through hashing is of the utmost importance so as to reduce the capacity for tampering, corruption, or potential for data poisoning.
References
Useful standards include:
- ISO 27001 Information Security Management System does not cover development-environment security explicitly. Nevertheless, the information security management system is designed to take care of it, provided that the relevant assets and their threats are taken into account. Therefore it is important to add train/test/validation data, model parameters and technical documentation to the existing development environment asset list.
#SEGREGATE DATA
Category: development-time information security control
Permalink: https://owaspai.org/go/segregatedata/
Description
Segregate data: store sensitive development data (training or test data, model parameters, technical documentation) in separated areas with restricted access. Each separate area can then be hardened accordingly and access granted to only those that need to work with that data directly.
Implementation
Examples of areas in which training data can be segregated:
- External - for when training data is obtained externally
- Application development environment: for application engineers that perhaps need to work with the actual training data, but require different access rights (e.g., don’t need to change it)
- Data engineering environment: for engineers collecting and processing the data.
- Training environment: for engineers training the model with the processed data. In this area, controls can be applied against risks that involve access to the other less-protected development areas. That way, for example data poisoning can be mitigated.
- Operational environment - for when training data is collected in operation
For more development environment security, see DEVSECURITY.
References
Useful standards include:
- ISO 27002 control 8.31 Separation of development, test and production environments. Gap: covers this control partly - the particularity is that the development environment typically has the sensitive data instead of the production environment - which is typically the other way around in non-AI systems. Therefore it helps to restrict access to that data within the development environment. Even more: within the development environment further segregation can take place to limit access to only those who need the data for their work, as some developers will not be processing data.
- See the ‘How’ section above for further standard references
#CONF COMPUTE
Category: development-time information security control
Permalink: https://owaspai.org/go/confcompute/
Description
Confidential compute: If available and possible, use features of the data science execution environment to hide training data and model parameters from model engineers - even while it is in use.
References
Useful standards include:
- Not covered yet in ISO/IEC standards
#FEDERATED LEARNING
Category: development-time AI engineer control
Permalink: https://owaspai.org/go/federatedlearning/
Description
Federated learning can be applied when a training set is distributed over different organizations, preventing the data from needing to be collected in a central place. This decreases the risk of all data leaking and increases the risk of some data leaking.
Federated Learning is a decentralized Machine Learning architecture wherein a number of clients (e.g., sensor or mobile devices) participate in collaborative, decentralized, asynchronous training, which is orchestrated and aggregated by a controlling central server. Advantages of Federated Learning include reduced central compute, and the potential for preservation of privacy, since training data may remain local to the client.
Broadly, Federated Learning generally consists of four high-level steps: First, there is a server-to-client broadcast; next, local models are updated on the client; once trained, local models are then returned to the central server; and finally, the central server updates via model aggregation.
Implementation
Federated machine learning benefits & use cases
Federated machine learning may offer significant benefits for organizations in several domains, including regulatory compliance, enhanced privacy, scalability and bandwidth, and other user/client considerations.
- Regulatory compliance. In federated machine learning, data collection is decentralized, which may allow for greater ease of regulatory compliance. Decentralization of data may be especially beneficial for international organizations, where data transfer across borders may be unlawful.
- Enhanced confidentiality. Federated learning can provide enhanced confidentiality, as data does not leave the client, reducing the potential for exposure of sensitive information. However, data can still be reconstructed from weights by a knowledgeable attacker (i.e. the central party in the FL protocol), so sensitive data exposure is still not guaranteed.
- Scalability & bandwidth. Decreased training data transfer between client devices and central server may provide significant benefits for organizations where data transfer costs are high. Similarly, federation may provide advantages in resource-constrained environments where bandwidth considerations might otherwise limit data uptake and/or availability for modeling. Further, because federated learning optimizes network resources, these benefits may on aggregate allow for overall greater capacity & flexible scalability.
- Data diversity. Because federated learning relies on a plurality of models to aggregate an update to the central model, it may provide benefits in data & model diversity. The ability to operate efficiently in resource-constrained environments may further allow for increases in heterogeneity of client devices, further increasing the diversity of available data.
Challenges in federated machine learning
- Remaining risk of data disclosure by the model. Care must be taken to protect against data disclosure by use threats (e.g., membership inference), as sensitive data may still be extracted from the model/models. Therefore, model theft threats also need mitigation, as training data may be disclosed from a stolen model. The federated learning architecture has specific attack surfaces for model theft in the form of transferring the model from client to server and storage of the model at the server. These require protection.
- Federated learning does not sufficiently protect the client’s data against the central party. An active and dishonest central party could extract user data from the received gradients by manipulating shared weights and isolating the user’s training data by computing deltas between the client’s weights and the central weights. Minimization and obfuscation (e.g., adding noise) is necessary to protect user’s data from the central party.
- More attack surface for poisoning. Security concerns also include attacks via data/model poisoning; with federated systems additionally introducing a vast network of clients, some of which may be malicious.
- Device Heterogeneity. User- or other devices may vary widely in their computational, storage, transmission, or other capabilities, presenting challenges for federated deployments. These may additionally introduce device-specific security concerns, which practitioners should take into consideration in design phases. While designing for constraints including connectivity, battery life, and compute, it is also critical to consider edge device security.
- Broadcast Latency & Security. Efficient communication across a federated network introduces additional challenges. While strategies exist to minimize broadcast phase latency, they must also take into consideration potential data security risks. Because models are vulnerable during transmission phases, any communication optimizations must account for data security in transit.
- Querying the data creates a risk. When collected data is stored on multiple clients, central data queries may be required for analysis work, next to Federated learning. Such queries would need the server to have access to the data at all clients, creating a security risk. In order to analyse the data without collecting it, various Privacy-preserving techniques exist, including cryptographic and information-theoretic strategies, such as Secure Function Evaluation (SFE), also known as Secure Multi-Party Computation (SMC/SMPC). However, all approaches entail tradeoffs between privacy and utility.
References
- OpenCRE: Federated learning referring to:
- Boenisch, Franziska, Adam Dziedzic, Roei Schuster, Ali Shahin Shamsabadi, Ilia Shumailov, and Nicolas Papernot. “When the curious abandon honesty: Federated learning is not private.” In 2023 IEEE 8th European Symposium on Security and Privacy (EuroS&P), pp. 175-199. IEEE, (2023). Link
- Sun, Gan, Yang Cong, Jiahua Dong, Qiang Wang and Ji Liu. “Data Poisoning Attacks on Federated Machine Learning.” IEEE Internet of Things Journal 9 (2020): 11365-11375. Link
- Wahab, Omar Abdel, Azzam Mourad, Hadi Otrok and Tarik Taleb. “Federated Machine Learning: Survey, Multi-Level Classification, Desirable Criteria and Future Directions in Communication and Networking Systems.” IEEE Communications Surveys & Tutorials 23 (2021): 1342-1397. Link
- Yang, Qiang, Yang Liu, Tianjian Chen and Yongxin Tong. “Federated Machine Learning.” ACM Transactions on Intelligent Systems and Technology (TIST) 10 (2019): 1 - 19. Link (One of the most highly cited papers on FML. More than 1,800 citations.)
Useful standards include:
- Not covered yet in ISO/IEC standards
#SUPPLY CHAIN MANAGE
Category: development-time information security control
Permalink: https://owaspai.org/go/supplychainmanage/
Description
Supply chain management focuses on managing the supply chain to minimize the security risk from externally obtained elements. In conventional software engineering these elements are source code or software components (e.g., open source). AI supply chains differ from conventional software supply chains in several ways:
- three new supplied assets: data, models, and model hosting. Note that models can also be delivered in the form of finetuning artifacts (e.g., LoRA modules);
- They supply chain may include the own organization instead of just third parties. For example, data and models may come from different departments and sources. This effectively makes supply chain management include for example data provenance.
- new AI-specific development tooling is typically required;
- some of these tools are executed development-time instead of runtime when the AI system is in production, introducing risks of development-time assets being attacked if these tools are corrupted (including training data and model parameters).
Because of these characteristics, classic supply chain management may not fully cover AI development environments, particularly notebook-based workflows and MLOps tooling.
Objective
The objective of supply chain management in AI systems is to reduce the risk of corrupted, compromised, outdated, or mismanaged externally provided components and services. This includes supplied assets such as data, models, libraries, and tools, as well as hosted AI models and AI services operated by third parties. Risk reduction is achieved through verification, continuous monitoring, and governance of these components and their providers across the AI system lifecycle. Compromises or misconfigurations could lead to unwanted model behavior, data exfiltration, service disruption, or loss of control over critical functionality.
Effective AI supply chain management helps to:
- identify compromised, poisoned, or untrustworthy data, models, and externally provided AI services before use,
- detect unauthorized modifications to AI assets, APIs, model endpoints, or service configurations,
- assess and monitor risks introduced by hosted foundation models and third-party AI providers,
- limit the blast radius of upstream security failures, service outages, or malicious model updates,
- manage the impact of provider-driven changes, such as silent model updates or altered system behavior,
- enforce data handling requirements when using external AI services (e.g., training use, retention, logging),
- ensure traceability of which external models or services were used in which system version,
- support informed risk decisions when relying on external suppliers and AI service providers.
Applicability
This control applies throughout the AI system lifecycle, particularly during data acquisition, model sourcing, training, fine-tuning, and integration phases.
It is especially relevant when:
- data sets or models are obtained from external or partially trusted sources,
- models are transferred across organizations or teams (e.g., base model → fine-tuning vendor),
- development-time tools or dependencies have access to sensitive AI assets,
- supply chains span multiple suppliers, jurisdictions, or labeling pipelines.
Risk management determines when deeper governance or verification is warranted, especially for threats related to supply chain compromise, poisoning, or unauthorized modification.
Implementation
Implementation of provenance, record keeping, and traceability
The AI supply chain can be complex. Just like with obtained source code or software components, data, models and model hosting may involve multiple suppliers. For example: a model is trained by one vendor and then fine-tuned by another vendor. Or: an AI system contains multiple models, one is a model that has been fine-tuned with data from source X, using a base model from vendor A that claims data is used from sources Y and Z, where the data from source Z was labeled by vendor B. Because of this supply chain complexity, data and model provenance is a helpful activity.
Maintaining structured records for AI-specific assets and services helps establish provenance and accountability across the supply chain. Relevant information includes:
- origin and versioning of models and datasets (provenance) including pre-trained model lineage,
- checksums or hashes to identify specific instances,
- training data sources and augmentation steps and data used to augment training data,
- dependencies and environment requirements (e.g. hardware, frameworks, packages, etc.) relevant to security,
- ownership, authorship, and responsible teams or suppliers.
Such records are often referred to as Model Cards, AIBOMs, or MBOMs, and can complement traditional SBOM practices by including AI-specific artifacts.
Implementation of lifecycle-aware record updates
Provenance and traceability records benefit from being updated at meaningful points in the AI system lifecycle. Typical update points include initial model development, major model version releases, pre-production deployment, significant architecture changes, introduction of new training datasets, and critical dependency updates. Additional checkpoints may be defined based on team practices or risk posture.Making these update points explicitly helps ensure records remain accurate as models, data, and dependencies evolve over time.
Implementation of Integrity, verification, and vulnerability management
Supply chain management benefits from verifying the integrity and authenticity of supplied data and models. Common techniques include:
- checksum or hash verification,
- signed attestations and integrity metadata,
- content-addressable storage or verification at read time,
- periodic integrity audits.
Monitoring for known vulnerabilities affecting supplied models, data pipelines, and dependencies, based on regular review of relevant security advisories and communications, allows teams to respond to newly discovered risks in a timely manner, informed by severity and exploitability, through updates, containment, or compensating controls. These activities can be integrated into broader vulnerability management and incident response processes (see #DEV SECURITY).
Implementation of supplier evaluation and security assessment of supplied models and model hosting
Evaluating the trustworthiness of suppliers (external vendors or internal teams) helps contextualize supply chain risk. This may include reviewing:
- reputation,
- activity,
- supplier security posture,
- development environments and access controls over AI assets,
- provenance claims for data and models,
- contractual assurances or warranties.
Models obtained from less trusted sources may warrant additional assessment, such as:
- validating model formats and serialization to avoid unsafe loading,
- inspecting architectures and layers for unexpected or custom components,
- testing runtime behavior in isolated environments to observe resource usage, system calls, or network activity.
Additional assessment activities may include inspecting model artifacts prior to execution to reduce the risk of unsafe loading. This can involve validating file formats and signatures, scanning for suspicious opcodes or serialized patterns associated with operating system commands, subprocess invocation, or file access, and checking for corruption using checksums or error handling.
Architecture inspection may include listing model layers without loading the model, identifying unknown, custom, or dynamically executed components, and reviewing model graphs for unexpected structures.
Runtime behavior testing can be performed in isolated or sandboxed environments by executing standard validation inputs or randomized probes while monitoring system resources, runtime calls, and network activity for suspicious behavior.
These assessments help reduce the risk of backdoors, malicious payloads, or poisoned artifacts entering the system.
Implementation of further practices to strengthen supply chain governance
In addition to basic provenance and integrity controls, teams may choose to enrich supply chain governance with more detailed documentation and process integration. Examples include:
- Expanded asset records: Records for data sets and models can include additional contextual information such as processing and transformation steps, tools and methods used, model architecture details, training configurations or parameters, ownership and authorship, licensing information, and records of which actors or groups had access to the asset throughout its lifecycle. This additional context can improve auditability and post-incident analysis.
- Contractual and legal risk coverage: Risks related to externally supplied data or models can be addressed not only technically but also contractually. Warranties, terms and conditions, usage instructions, or supplier agreements can explicitly cover expectations around data provenance, security practices, and liability for compromised or misrepresented assets.
- Integration with configuration and version management: Relevant code, configuration, documentation, and packaged artifacts can be included as part of the traceability process and linked to existing version control and configuration management systems. This helps ensure that changes to models, data, or dependencies remain auditable and reproducible.
- Alignment with vulnerability management processes: Monitoring and remediation of vulnerabilities affecting data, models, and AI-specific dependencies can be integrated into the same processes used for tracking and patching software components. This reduces fragmentation and helps ensure that AI assets are considered alongside traditional software dependencies.
Risk-Reduction Guidance
Supply chain management reduces risk by adding scrutiny and visibility to what the AI system depends on. Understanding where data and models originate, how they were produced, and how they change over time makes it harder for compromised components to remain undetected.
Residual risk depends on:
- the number and trustworthiness of suppliers,
- the depth of provenance and verification practices,
- the effectiveness of integrity protections,
- the ability to respond quickly to newly discovered vulnerabilities.
As with traditional software supply chains, governance does not eliminate risk but helps detect, contain, and respond to supply chain issues earlier and with lower impact.
Particularity
Unlike conventional software supply chains, AI supply chains include non-code artifacts (data, models, fine-tuning adapters) and development-time execution paths that expose sensitive assets. This makes governance of notebooks, MLOps tools, and training environments particularly important.
Supply chain controls therefore extend beyond runtime binaries and must consider how AI assets are created, transformed, and reused across the lifecycle.
Limitations
Supply chain management relies on the accuracy and completeness of records and attestations. False or incomplete provenance claims, compromised suppliers, or insufficient visibility into upstream processes can limit effectiveness.
Complex multi-party supply chains may make full traceability difficult, and trust decisions often remain probabilistic rather than absolute.
References
- OpenCRE: AI supply chain management referring to:
See MITRE ATLAS - ML Supply chain compromise.
Useful standards include:
- ISO Controls 5.19, 5.20, 5.21, 5.22, 5.23, 8.30. Gap: covers this control fully, with said particularity, and lacking controls on data provenance.
- ISO/IEC 24368:2022 and ISO/IEC 24030:2024.
- ISO/IEC AWI 5181 (Data provenance). Gap: covers the data provenance aspect to complete the coverage together with the ISO 27002 controls - provided that the provenance concerns all sensitive data and is not limited to personal data.
- ISO/IEC 42001 (AI management) briefly mentions data provenance and refers to ISO 5181 in section B.7.5
- ETSI GR SAI 002 V 1.1.1 Securing Artificial Intelligence (SAI) – Data Supply Chain Security
- OpenCRE
3.1. Broad model poisoning development-time
Category: group of development-time threats
Permalink: https://owaspai.org/go/modelpoison/
Description
Development-time model poisoning in the broad sense is when an attacker manipulates development elements (the engineering environment and the supply chain), to alter the behavior of the model. There are three types, each covered in a subsection:
- data poisoning: an attacker manipulates training data, or data used for in-context learning.
- development-environment model poisoning: an attacker manipulates model parameters, or other engineering elements that take part in creating the model, such as code, configuration or libraries.
- supply-chain model poisoning: using a supplied trained model which has been manipulated by an attacker.
Impact: Integrity of model behaviour is affected, leading to issues from unwanted model output (e.g., failing fraud detection, decisions leading to safety issues, reputation damage, liability).
Data and model poisoning can occur at various stages, as illustrated in the threat model below.
- Supplied data or a supplied model can have been poisoned
- Poisoning in the development environment can occur in the data preparation domain, or in the training environment. If the training environment is separated security-wise, then it is possible to implement certain controls (including tests) against data poisoning that took place at the supplier or during preparation time.
- In the case that training data is collected at runtime, then this data is under poisoning threat.
- Model poisoning alters the model directly, either at the supplier, or development-time, or during runtime.
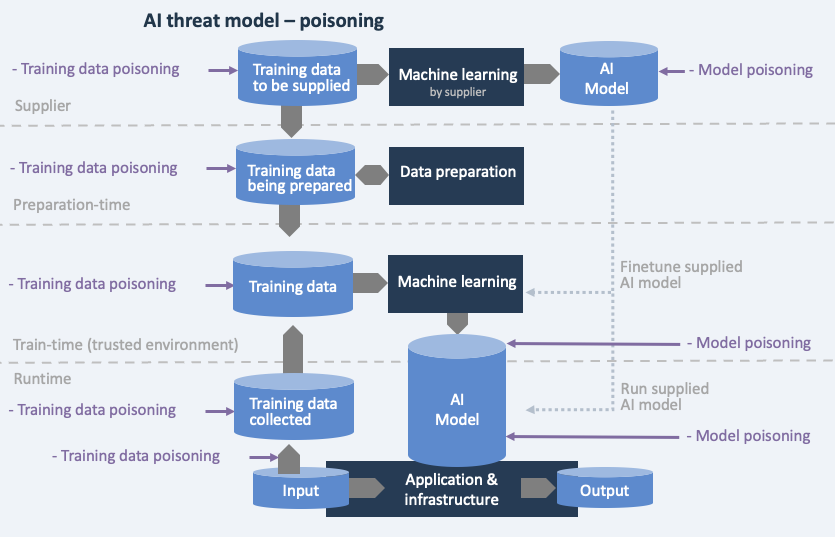
Controls for broad model poisoning:
- especially Limiting the effect of unwanted behaviour
Controls for development-time protection:
- #DEV SECURITY to protect the development environment
- #SEGREGATE DATA to create parts of the development environment with extra protection
- #CONF COMPUTE for denying access to where sensitive data is processed
- #SUPPLY CHAIN MANAGE especially to control where data and models come from
Controls for data poisoning:
- MORETRAINDATA to try and overrule poisoned data
- DATAQUALITYCONTROL to try and detect or prevent poisoned data
- TRAINDATADISTORTION to try and corrupt poisoned data
- POISONROBUSTMODEL to reduce the ability to recall poisoned data
- Controls that are aimed to improve the generalization ability of the model - reducing the memorization of any poisoned samples: training with adversarial samples and adversarial robust distillation
Controls specific to broad model poisoning - discussed below
- MODELENSEMBLE so that if one of the models is poisoned, it can be contained
#MODEL ENSEMBLE
Category: development-time AI engineer control - including specific runtime implementation Permalink: https://owaspai.org/go/modelensemble/
Description
Model ensemble: deploy the model as an ensemble of models by randomly splitting the trainset to allow detection of poisoning. If one model’s output deviates from the others, it can be ignored, as this indicates possible manipulation of the train set.
Effectiveness: the more the dataset has been poisoned with samples, the less effective this approach is.
Ensemble learning is a term in machine learning used for using multiple learning algorithms, with the purpose of better predictive performance.
References
- OpenCRE: Ensemble AI models referring to:
Useful standards include:
- Not covered yet in ISO/IEC standards
3.1.1. Data poisoning
Category: development-time threat
Permalink: https://owaspai.org/go/datapoison/
Description
An attacker manipulates data that the model uses to learn, in order to affect the algorithm’s behavior. Also called causative attacks. There are multiple ways to do this (see the attack surface diagram in the broad model poisoning section):
- Changing the data while in storage during development-time (e.g., by hacking the database)
- Changing the data while in transit to the storage (e.g., by hacking into a data transfer)
- Changing the data while at the supplier, before the data is obtained from the supplier
- Changing the data while at the supplier, where a model is trained and then that model is obtained from the supplier
- Manipulating data entry in operation, feeding into training data, for example by creating fake accounts to enter positive reviews for products, making these products get recommended more often
- Several of the above attack types are very much possible if executed by an insider attacker
The manipulated data can be training data, but also in-context-learning data that is used to augment the input (e.g., a prompt) to a model with information to use. Collaborative mitigations like #FEDERATED LEARNING can reduce data centralization but require additional poisoning controls based on extension of attack surface.
Example 1: an attacker breaks into a training set database to add images of houses and labels them as ‘fighter planes’, to mislead the camera system of an autonomous missile. The missile is then manipulated to attack houses. With a good test set this unwanted behaviour may be detected. However, the attacker can also perform so-called targeted data poisoning by making the poisoned data represent input that normally doesn’t occur and therefore would not be in a testset. The attacker can then create that abnormal input in practice. In the previous example this could be houses with white crosses on the door. See MITRE ATLAS - Poison trainingdata
Example 2: a malicious supplier poisons data that is later obtained by another party to train a model. See MITRE ATLAS - Publish poisoned datasets
Example 3: unwanted information (e.g. false facts) in documents on the internet causes a Large Language Model (GenAI) to output unwanted results (OWASP for LLM 04). That unwanted information can be planted by an attacker, but of course also by accident. The latter case is a real GenAI risk, but technically comes down to the issue of having false data in a training set which falls outside of the security scope. Planted unwanted information in GenAI training data falls under the category of Sabotage attack as the intention is to make the model behave in unwanted ways for regular input.
There are roughly two categories of data poisoning:
- Targeted data poisoning - which triggers unwanted responses to specific inputs (e.g., a money transaction is wrongfully marked as NOT fraud because it has a specific amount of money for which the model has been manipulated to ignore). Other names: Trojan attack or Backdoor.
- Sabotage: data poisoning leads to unwanted results for regular inputs, leading to e.g. business continuity problems or safety issues.
Sabotage data poisoning attacks are relatively easy to detect because they occur for regular inputs, but backdoor data poisoning only occurs for really specific inputs and is therefore hard to detect: there is no code to review in a model to look for backdoors, the model parameters cannot be reviewed as they make no sense to the human eye, and testing is typically done using normal cases, with blind spots for backdoors. This is the intention of attackers - to bypass regular testing.
Controls for data poisoning:
- General controls,
- especially Limiting the effect of unwanted behaviour
- Controls for development-time protection:
- #DEV SECURITY to protect the development environment and primarily the training data
- #SEGREGATE DATA to create parts of the development environment with extra protection
- #CONF COMPUTE for denying access to where sensitive data is processed
- #SUPPLY CHAIN MANAGE especially to control where data and models come from
- Controls for data poisoning - discussed below:
- MORETRAINDATA to try and overrule poisoned data
- DATAQUALITYCONTROL to try and detect or prevent poisoned data
- TRAINDATADISTORTION to try and corrupt poisoned data
- POISONROBUSTMODEL to reduce the ability to recall poisoned data
- Controls that are aimed to improve the generalization ability of the model - reducing the memorization of any poisoned samples: training with adversarial samples and adversarial robust distillation
References
- OpenCRE: Data poisoning of train/finetune/augmentation data
referring to:
- OWASP Top10 for LLM: sec. LLM04:2025: Data and Model Poisoning
- MITRE ATLAS: sec. AML.T0020: Poison Training Data
- ETSI: sec. 5.1: Poisoning attacks
- ENISA: sec. Table 3:: Poisoning
- OWASP Top10 for ML: sec. ML02:2023: Data Poisoning Attack
- BIML: sec. BIML-78(2020): data:1: Data Poisoning
- NIST AI 100-2: sec. 2.3.2: Targeted Poisoning
- Summary of 15 backdoor papers at CVPR ‘23
- Badnets article by Gu et al
- Clean-label Backdoor attacks by Turner et al
#MORE TRAIN DATA
Category: development-time AI engineer control - pre-training
Permalink: https://owaspai.org/go/moretraindata/
Description
More train data: increasing the amount of non-malicious data makes training more robust against poisoned examples - provided that these poisoned examples are small in number. One way to do this is through data augmentation - the creation of artificial training set samples that are small variations of existing samples. The goal is to ‘outnumber’ the poisoned samples so the model ‘forgets’ them. However, this also runs the risk of catastrophic forgetting, where also benign data points (especially those out of distribution) are lost. Also, watch out for overfitting which is another potential side effect to this control.
This control can only be applied during training and therefore not to an already trained model. Nevertheless, a variation can be applied to a trained model: by fine-tuning it with additional non-malicious data - see POISONROBUSTMODEL.
References
- OpenCRE: Benign train data increase referring to:
Useful standards include:
- Not covered yet in ISO/IEC standards
#DATA QUALITY CONTROL
Category: development-time AI engineer control - pre-training
Permalink: https://owaspai.org/go/dataqualitycontrol/
Description
Data quality control: Perform quality control on data including detecting poisoned samples through integrity checks, statistical deviation or pattern recognition.
Standard data quality checks are not sufficient for AI systems, as data may be maliciously altered to compromise model behavior. This requires different checks than standard checks on quality issues from the source, or that occurred by mistake. Nevertheless, standard checks can help somewhat to detect malicious changes.
Objective
Data quality control aims to reduce the risk of data poisoning by identifying anomalous or manipulated training samples before they influence model behavior i.e. before training and before augmentation of input. Poisoned samples can be introduced intentionally to manipulate the model, and early detection helps prevent persistent or hard-to-reverse impacts on model integrity.
Applicability
This control applies during data preparation, training, and data augmentation phases. It cannot be applied retroactively to a model that has already been trained. Implementing it during training ensures that the model learns from clean, high-quality data, thus enhancing its performance and security. This is key to know and implement early on in the training process to ensure adequate training results and long-term success in the overall quality of the data.
Its applicability depends on the assessed risk of data poisoning, including sabotage poisoning and trigger-based poisoning. In some cases, anomaly detection thresholds may prove ineffective at distinguishing poisoned samples from benign data (FP risk), in which case alternative or complementary controls may be more appropriate.
When anomaly detection thresholds consistently fail to distinguish poisoned samples from benign data, reliance on alternative or complementary controls may be more effective. Implementation may be more suitable for the deployer of the AI system in environments where training data pipelines or supply chains are externally managed.
Implementation
Implementation of standard data quality controls Standard data quality controls include:
- Validation: regularly verify if data satisfies requirements regarding format and being in the allowed range of values
- Versioning and rollback mechanisms in order to pinpoint quality incidents and restore data
- Data provenance (see SUPPLY CHAIN MANAGE)
Implementation of integrity checks
Safely store hash codes of data elements and conduct regular checks for manipulations. See DEVSECURITY for more details on integrity checks.
Implementation of Detecting anomalous training samples
Training data can be analyzed to identify samples that deviate from expected distributions or patterns. Poisoned samples may differ statistically or structurally from the rest of the dataset, making anomaly detection a useful signal.
Deviation detection can be applied:
- to newly added samples before training or augmentation, and
- to existing samples already present in the training dataset.
Different methods can be used to detect anomalous or poisoned samples, including:
- statistical deviation and outlier detection methods,
- spectral signatures based on covariance of learned feature representations,
- activation clustering, where poisoned triggers produce distinct neuron activation patterns,
- Reject on Negative Impact (RONI), which evaluates the impact of individual samples on model performance, and
- gradient fingerprinting, which compares the influence of samples during retraining.
See the #ANOMALOUS INPUT HANDLING control for more details.
The appropriateness of a method depends on the poisoning threat model and can be assessed through targeted testing, including poisoned dataset benchmarks and resistance testing.
Detected anomalies can be handled in different ways depending on the degree of deviation:
- samples that strongly deviate from expected behavior may be filtered out of the training data to reduce poisoning risk,
- samples that moderately deviate may trigger alerts for further investigation, allowing identification of attack sources or pipeline weaknesses.
Thresholds for detection are typically established through experimentation to balance detection effectiveness and model correctness. Using multiple thresholds (for filtering versus alerting) helps balance false positives, investigation effort, and model accuracy.
Implementation of detection mechanism protection
Detection mechanisms and the data they rely on benefit from protection against manipulation, especially in environments where attackers may target the development pipeline or supply chain. Segregation of development environments and integrity protections can help prevent attackers from tampering with detection logic.
Implementation considerations
- Proactive Approach: Implement data quality controls during the training phase to prevent issues before they arise in production.
- Comprehensive Verification: Combine automated methods with human oversight for critical data, ensuring that anomalies are accurately identified and addressed.
- Continuous Monitoring: Regularly update and audit data quality controls to adapt to evolving threats and maintain the robustness of AI systems.
- Collaboration and Standards: Adhere to international standards like ISO/IEC 5259 and 42001 while recognizing their limitations.
Risk-Reduction Guidance
Filtering anomalous training samples can reduce the probability of successful data poisoning, particularly when poisoned samples introduce unusual triggers or patterns. Effectiveness depends on the representativeness of the data, the quality of deviation metrics, and the chosen thresholds.
Testing detection approaches on known poisoned datasets can help assess their effectiveness and validate implementation choices.
Particularity
Standard data quality checks are not sufficient for AI systems, as data may be maliciously altered to compromise model behavior. This requires different checks than standard checks on quality issues from the source, or that occurred by mistake. Nevertheless, standard checks (e.g., is the data in the correct format) help to some extent to detect malicious changes.
Limitations
Anomaly detection involves trade-offs:
- false positives may lead to unnecessary investigation or removal of rare but valid samples, potentially harming model accuracy,
- false negatives may occur when poisoned samples closely resemble normal data and evade detection.
Sophisticated attackers can design poisoned samples to blend into the normal data distribution, reducing the effectiveness of purely anomaly-based approaches.
References
- OpenCRE: Data quality control referring to:
- GS1 Data quality framework
- IBM on data quality in AI
- SAND on data quality vs integrity
- ‘Detection of Adversarial Training Examples in Poisoning Attacks through Anomaly Detection’
Useful standards include:
- ISO/IEC 25012:2008(E) on Data quality characteristics (Accuracy, completeness, consistency, currentness, credibility)
- ISO/IEC 5259 series on Data quality for analytics and ML. Gap: covers this control minimally. in light of the particularity - the standard does not mention approaches to detect malicious changes (including detecting statistical deviations). Nevertheless, standard data quality control helps to detect malicious changes that violate data quality rules.
- ISO/iEC 42001 B.7.4 briefly covers data quality for AI. Gap: idem as ISO 5259
- Not further covered yet in ISO/IEC standards
#TRAIN DATA DISTORTION
Category: development-time AI-engineer control - pre-training
Permalink: https://owaspai.org/go/traindatadistortion/
Description
Train data distortion: distorting untrusted training data by smoothing or adding noise.
Objective
Distorting training data intends to make poisoned ’triggers’ ineffective. Such a trigger has been inserted by an attacker in the training data, together with an unwanted output. Whenever input data is presented that contains a similar ’trigger’, the model can recognize it and output the unwanted value. The idea is to distort the triggers so that they are not recognized anymore by the model. The idea is essentially the same as in #INPUTDISTORTION, where it is used to defend against evasion attacks and data poisoning.
Implementation
Distortion can be performed by e.g. adding noise (randomization), smoothing. For images, JPEG compression can be considered .
See also EVASIONROBUSTMODEL on adding noise against evasion attacks and OBFUSCATETRAININGDATA to minimize data for confidentiality purposes - which can serve two purposes: privacy and data poisoning mitigation.
A special form of train data distortion is complete removal of certain input fields. Technically, this is data minimization (see DATAMINIMIZE), but its purpose is not protecting the confidentiality of that data per se, but reducing the ability to memorize poisoned samples.
This control can only be applied during training and therefore not to an already pre-trained model.
Risk-Reduction Guidance
- The level of effectiveness needs to be tested by experimenting, which will not give conclusive results, as an attacker may find more clever ways to poison the data than the methods used during testing. It is a best practice to keep the original training data, in order to experiment with the amount or distortion.
- This control has no effect against attackers that have direct access to the training data after it has been distorted. For example, if the distorted training data is stored in a file or database to which the attacker has access, then the poisoned samples can still be injected. In other words: if there is zero trust in protection of the engineering environment, then train data distortion is only effective against data poisoning that took place outside the engineering environment (collected during runtime or obtained through the supply chain). This problem can be reduced by creating a trusted environment in which the model is trained, separated from the rest of the engineering environment. By doing so, controls such as train data distortion can be applied in that trusted environment and thus protect against data poisoning that may have taken place in the rest of the engineering environment.
Examples
- Transferability blocking. The true defense mechanism against closed box attacks is to obstruct the transferability of the adversarial samples. The transferability enables the usage of adversarial samples in different models trained on different datasets. Null labeling is a procedure that blocks transferability, by introducing null labels into the training dataset, and trains the model to discard the adversarial samples as null labeled data.
- DEFENSE-GAN: Defense-GAN attempts to “purify” images (adversarial attacks) by mapping them to the manifold of valid, unperturbed inputs.
- Local intrinsic dimensionality. Poisoned samples often exhibit distinct local characteristics, such as being outliers or lying in a subspace with abnormal properties, which result in anomalously high or low LID scores. By computing LID scores during training, poisoned data points can be identified and removed, allowing the model to train robustly on clean data.
- (weight)Bagging - see Annex C in ENISA 2021. By training multiple models on different subsets of the training data, the impact of poisoned samples is diluted across the ensemble. By combining predictions, bagging reduces the influence of any single poisoned sample, enhancing the robustness of the overall system against data poisoning attacks.
- TRIM algorithm - see Annex C in ENISA 2021. The TRIM algorithm is a defense mechanism against data poisoning attacks that identifies and removes potentially poisoned samples from a dataset. It iteratively trains a model while excluding data points that contribute disproportionately to the loss, as these are likely to be outliers or poisoned samples. By focusing on minimizing the loss for the remaining data, TRIM ensures robust training by reducing the impact of maliciously crafted inputs.
- STRIP technique (after model evaluation) - see Annex C in ENISA 2021. STRIP is a detection method for backdoor attacks. It works by applying random perturbations to input samples and measuring the model’s prediction entropy; backdoored inputs typically produce consistently low entropy, as the trigger enforces a fixed output regardless of the perturbations. By flagging inputs with anomalously low entropy, STRIP effectively identifies and mitigates the influence of backdoor attacks during inference.
References
- OpenCRE: Train data distortion referring to:
Useful standards include:
- Not covered yet in ISO/IEC standards
#POISON ROBUST MODEL
Category: development-time AI engineer control - post-training
Permalink: https://owaspai.org/go/poisonrobustmodel/
Description
Poison robust model: select a model type and creation approach to reduce sensitivity to poisoned training data.
Applicability
This control can be applied to a model that has already been trained, including models that have been obtained from an external source.
Implementation
The general principle of reducing sensitivity to poisoned training data is to make sure that the model does not memorize the specific malicious input pattern (or backdoor trigger). The following two examples represent different strategies, which can also complement each other in an approach called fine pruning (See paper on fine-pruning):
- Reduce memorization by removing elements of memory using pruning. Pruning in essence reduces the size of the model so it does not have the capacity to trigger on backdoor-examples while retaining sufficient accuracy for the intended use case. The approach removes neurons in a neural network that have been identified as non-essential for sufficient accuracy.
- Overwrite memorized malicious patterns using fine-tuning by retraining a model on a clean dataset(without poisoning). A specific approach to this is Selective Amnesia, which is a two-step continual learning approach to remove backdoor effects from a compromised model by inducing targeted forgetting of both the backdoor task and primary task, followed by restoration of only the primary functionality.
- Inducing forgetting: Retrain (fine-tune) the compromised model using clean data with randomized labels. This step causes the model to forget both its primary task and any backdoor tasks that were embedded during poisoning. The randomized labels disrupt the learned associations, effectively erasing the model’s memory of both legitimate and malicious patterns.
- Restoring primary functionality: Subsequently retrain (fine-tune) the model with a small subset of correctly labeled clean data to recover its intended functionality. This step restores the model’s ability to perform its primary task while drastically reducing likelihood that backdoor triggers activate the malicious behavior.
- Effectiveness and efficiency: Selective amnesia requires only a small fraction of clean data (e.g., 0.1% of the original training data) to effectively remove backdoor effects, making it practical even when limited clean data is available. The method is computationally efficient, being approximately 30 times faster than training a model from scratch on the MNIST dataset, while achieving high fidelity in removing backdoor influences. Unlike some other remediation techniques, selective amnesia does not require prior knowledge of the backdoor trigger pattern, making it effective against unknown backdoor attacks.
References
- OpenCRE: Benign fine-tuning and pruning referring to:
Useful standards include:
- Not covered yet in ISO/IEC standards
#TRAIN ADVERSARIAL
Category: development-time AI engineer control - pre-training
Permalink: https://owaspai.org/go/trainadversarial/
Description
Training with adversarial examples is used as a control against evasion attacks, but can also be helpful against data poison trigger attacks that are based on slight alterations of training data, since these triggers are like adversarial samples.
For example: adding images of stop signs in a training database for a self-driving car, labeled as 35 miles an hour, where the stop sign is slightly altered. What this effectively does is to force the model to make a mistake with traffic signs that have been altered in a similar way. This type of data poisoning aims to prevent anomaly detection of the poisoned samples.
Find the corresponding control section here, with the other controls against Evasion attacks.
References
- OpenCRE: Adversarial training referring to:
- ‘How to adversarially train against data poisoning’
- ‘Is Adversarial Training Really a Silver Bullet for Mitigating Data Poisoning?’
3.1.2. Direct development-time model poisoning
Category: development-time threat
Permalink: https://owaspai.org/go/devmodelpoison/
Description
This threat refers to manipulating behaviour of the model NOT by n poisoning the training data, but instead by manipulating elements in the development-environment that lead to the model or represent the model (i.e. model attributes), e.g. by manipulating storage of model parameters or placing the model with a completely different one with malicious behavior, injection of malware (command or code injection) through custom or lambda layers, manipulating the model weights and modifying the model architecture, embedding deserialization attacks, which could execute stealthily during model unpacking or model execution. When the model is trained by a supplier in a manipulative way and supplied as-is, then it is supply-chain model poisoning.
Training data manipulation is referred to as data poisoning. See the attack surface diagram in the broad model poisoning section.
Controls
- General controls,
- especially Limiting the effect of unwanted behaviour
- Controls for development-time protection:
- #DEV SECURITY to protect the development environment and primarily the model parameters
- #SEGREGATE DATA to create parts of the development environment with extra protection
- #CONF COMPUTE for denying access to where sensitive data is processed
- #SUPPLY CHAIN MANAGE especially to control where data and models come from
- Controls for model performance validation to detect deviation: #CONTINUOUS VALIDATION
3.1.3 Supply-chain model poisoning
Category: development-time threat
Permalink: https://owaspai.org/go/supplymodelpoison/
Description
An attacker manipulates a third-party (pre-)trained model which is then supplied, obtained and unknowingly further used and/or trained/fine-tuned, while still having the unwanted behaviour (see the attack surface diagram in the broad model poisoning section). If the supplied model is used for further training, then the attack is called a transfer learning attack.
AI models are sometimes obtained elsewhere (e.g., open source) and then further trained or fine-tuned. These models may have been manipulated (poisoned) at the source, or in transit. See OWASP for LLM 03: Supply Chain.
The type of manipulation can be through data poisoning, or by specifically changing the model parameters. Therefore, the same controls apply that help against those attacks. Since changing the model parameters requires protection of the parameters at the moment they are manipulated, this is not in the hands of the one who obtained the model. What remains are the controls against data poisoning, the controls against model poisoning in general (e.g., model ensembles), plus of course good supply chain management including protective considerations of frameworks and tools as supply-chain components that can be poisoned.
Controls
- especially Limiting the effect of unwanted behaviour
From the controls for development-time protection: #SUPPLY CHAIN MANAGE to control where models come from
Controls for data poisoning post-training:
- POISONROBUSTMODEL to reduce the ability to recall poisoned data
- Adversarial robust distillation to improve the generalization ability of the model
Other controls need to be applied by the supplier of the model:
- Controls for development-time protection, like for example protecting the training set database against data poisoning
- Controls for broad model poisoning
#SUPPLY CHAIN MANAGE especially to components from frameworks and tools
3.2. Sensitive data leak development-time
Category: group of development-time threats
Permalink: https://owaspai.org/go/devleak/
3.2.1. Development-time data leak
Category: development-time threat
Permalink: https://owaspai.org/go/devdataleak/
Description
Unauthorized access to train or test data through a data leak of the development environment.
Impact: Confidentiality breach of sensitive train/test data.
Training data or test data can be confidential because it’s sensitive data (e.g., personal data) or intellectual property. An attack or an unintended failure can lead to this training data leaking. Training or test data theft means unauthorized access to exposure-restricted training or test data through stealing data from the development environment, including the supply chain.
Leaking can happen from the development environment, as engineers need to work with real data to train the model.
Sometimes training data is collected at runtime, so a live system can become an attack surface for this attack.
GenAI models are often hosted in the cloud, sometimes managed by an external party. Therefore, if you train or fine tune these models, the training data (e.g., company documents) needs to travel to that cloud.
Controls
- General controls,
- especially Sensitive data limitation
- Controls for development-time protection:
- #DEV SECURITY to protect the development environment and primarily the training and test data
- #SEGREGATE DATA to create parts of the development environment with extra protection
- #CONF COMPUTE for denying access to where sensitive data is processed
3.2.2. Direct development-time model leak
Category: development-time threat
Permalink: https://owaspai.org/go/devmodelleak/
Description
Unauthorized access to model attributes (e.g., parameters, weights, architecture) through stealing data from the development environment, including the supply chain. This can occur via insider access, compromised repositories, or weak storage controls
Impact: Confidentiality breach of the model (i.e., model parameters), which can be:
- intellectual property theft (e.g., by a competitor)
- and/or a way to perform input attacks on the copied model, circumventing protections. These protections include rate limiting, access control, and detection mechanisms. This can be done for all input attacks that extract data, and for the preparation of evasion or prompt injection: experimenting to find attack inputs that work.
Alternative ways of model theft are model exfiltration and direct runtime model leak.
Risk identification
This threat applies if the model represents intellectual property (i.e., a trade secret), or the risk of any input attack applies - with the exception of the model being publicly available because then there is no need to steal it.
Controls
- General controls,
- especially Sensitive data limitation
- Controls for development-time protection:
- #DEV SECURITY to protect the development environment and primarily the model parameters
- #SEGREGATE DATA to create parts of the development environment with extra protection
- #CONF COMPUTE for denying access to where sensitive data is processed
- #SUPPLY CHAIN MANAGE specifically protects model attributes
- Specifically for model theft:
3.2.3. Source code/configuration leak
Category: development-time threat
Permalink: https://owaspai.org/go/devcodeleak/
Description
Unauthorized access to code or configuration that leads to the model, through a data leak of the development environment. Such code or configuration is used to preprocess the training/test data and train the model.
Impact: Confidentiality breach of model intellectual property.
Controls
- General controls,
- especially Sensitive data limitation
- Controls for development-time protection:
- #DEV SECURITY to protect the development environment and primarily the source code/configuration
- #SEGREGATE DATA to create parts of the development environment with extra protection
