1. General controls
Edit pageCategory: group of controls
Permalink: https://owaspai.org/go/generalcontrols/
1.1 General governance controls
Category: group of controls
Permalink: https://owaspai.org/go/governancecontrols/
#AI PROGRAM
Category: governance control
Permalink: https://owaspai.org/go/aiprogram/
Description
AI program: Install and execute a program to govern AI.
One could argue that this control is out of scope for cybersecurity, but it initiates action to get in control of AI security.
Objective
The objective of an AI Program is to take responsibility for AI as an organization and make sure that all AI initiatives are known and under control, including their security.
Implementation
This governance challenge may seem daunting because of all the new things to take care of, but there are numerous existing controls in organizations already that can be extended to include AI (e.g. policies, risk analysis, impact analysis, inventory of used services etc.).
See How to organize AI security for the 5 GUARD steps and to see how governance fits into the whole.
An AI Program includes:
- Keeping an inventory of AI initiatives
- Perform impact analysis on initiatives
- Organize AI innovation
- Include AI risks in risk management
- Assign responsibilities, e.g. model accountability, data accountability, and risk governance
- AI literacy (e.g. training
- Organize compliance
- Incorporate AI assets in the security program
When doing impact analysis on AI initiatives, consider at least the following:
- Note that an AI program is not just about risks TO AI, such as security risks - it is also about risks BY AI, such as threats to fairness, safety, etc.
- Include laws and regulations, as the type of AI application may be prohibited (e.g. social scoring under the EU AI Act). See #CHECKCOMPLIANCE
- Can the required transparency be provided into how the AI works?
- Can the privacy rights be achieved (right to access, erase, correct, update personal data, and the right to object)?
- Can unwanted bias regarding protected groups of people be sufficiently mitigated?
- Is AI really needed to solve the problem?
- Is the right expertise available (e.g. data scientists)?
- Is it allowed to use the data for the purpose - especially if it is personal data collected for a different purpose?
- Can unwanted behaviour be sufficiently contained by mitigations (see Controls to limit unwanted behaviour)?
- See Risk management under SECPROGRAM for security-specific risk analysis, also involving privacy.
Quickstart
A typical first iteration for AI governance in organizations consists of the following:
- Raise attention and awareness at board level, when needed
- Form a group of stakeholders and assign responsibilities
- Identify laws and regulations
- Send out a survey to make an inventory of current AI use, AI ideas, any concerns, and individuals with AI expertise
- Evaluate these AI applications and ideas
- Perform a risk analysis and establish a first policy
- Implement policy as much as possible in tools and procedures
- Initiate an AI literacy program, based on the policy implementation plan
Bare minimum start The very minimum first thing you can do for AI governance, focused on security:
- Make an inventory of current AI use and AI ideas.
- Perform risk analysis on them to identify threats, controls and who’s responsible for them.
- Continue with step 2 of the GUARD program, presented in the How to organize section.
Particularity
In general risk management it may help to keep in mind the following particularities of AI:
- Inductive instead of deductive, meaning that being wrong is part of the game for machine learning models, which can lead to harm
- Connected to 1: models can go stale
- Organizes its behaviour based on data, so data becomes a source of opportunity (e.g. complex real-world problem-solving, adaptability) and of risk (e.g. unwanted bias, incompleteness, error, manipulation)
- Unfamiliar to organizations and to people, with the risk of implementation mistakes, underreliance, overreliance, and incorrect attribution of human tendencies
- Incomprehensible, resulting in trust issues
- New technical assets that form security threats (data/model supply chain, train data, model parameters, augmentation data, AI documentation)
- Can listen and speak: communicate through natural language instead of user interfaces
- Can hear and see: have sound and vision recognition abilities
References
- AI Governance library
- UNESCO on AI ethics and governance
- GenAI security project LLM AI Cybersecurity & governance checklist
Useful standards include:
- ISO/IEC 42001 AI management system. Gap: covers this control fully.
- US Federal Reserve SR 11-07: Guidance on Model Risk Management: supervisory guidance for banking organizations and supervisors.
42001 is about extending your risk management system - it focuses on governance. ISO 5338 (see #DEV PROGRAM below) is about extending your software lifecycle practices - it focuses on engineering and everything around it. ISO 42001 can be seen as a management system for the governance of responsible AI in an organization, similar to how ISO 27001 is a management system for information security. ISO 42001 doesn’t go into the lifecycle processes. For example, it does not discuss how to train models, how to do data lineage, continuous validation, versioning of AI models, project planning challenges, and how and when exactly sensitive data is used in engineering.
#SEC PROGRAM
Category: governance control
Permalink: https://owaspai.org/go/secprogram/
Description
Security Program: Make sure the organization has a security program (also referred to as information security management system) and that it includes the whole AI lifecycle and AI specific aspects.
Objective
Ensures adequate mitigation of AI security risks through information security management, as the security program takes responsibility for the AI-specific threats and corresponding risks. For more details on using this document in risk analysis, see the risk analysis section.
Implementation
Make sure to include AI-specific assets and the threats to them. The threats are covered in this resource and the assets are:
- training data
- validation data
- test data
- the model - often referred to as model parameters (values that change when a model is trained)
- hyperparameters
- documentation of models and the process of their development including experiments
- model input
- model output, which needs to be regarded as untrusted if the training data or model is untrusted
- intended model behaviour
- data to train and test obtained from external sources
- models to train and use from external sources
- augmentation data that is automatically inserted into the model input (e.g. documents, system prompts)
By incorporating these assets and the threats to them, the security program takes care of mitigating these risks. For example: by informing engineers in awareness training that they should not leave their documentation lying around. Or: by installing malware detection on engineer machines because of the high sensitivity of the training data that they work with.
Every AI initiative, new and existing, should perform a privacy and security risk analysis. AI programs have additional concerns around privacy and security that need to be considered. While each system implementation will be different based on its contextual purpose, the same process can be applied. These analyses can be performed before the development process and will guide security and privacy controls for the system. These controls are based on security protection goals such as Confidentiality, Integrity and Availability, and privacy goals such as Unlinkability, Transparency and Intervenability. ISO/IEC TR 27562:2023 provides a detailed list of points of attention for these goals and coverage.
The general process for performing an AI Use Case Privacy and Security Analysis is:
- Describe the Ecosystem
- Provide an assessment of the system of interest
- Identify the security and privacy concerns
- Identify the security and privacy risks
- Identify the security and privacy controls
- Identify the security and privacy assurance concerns
Because AI has specific assets (e.g. training data), AI-specific honeypots are a particularly interesting control. These are fake parts of the data/model/data science infrastructure that are exposed on purpose, in order to detect or capture attackers, before they succeed to access the real assets. Examples:
- Hardened data services, but with an unpatched vulnerability (e.g. Elasticsearch)
- Exposed data lakes, not revealing details of the actual assets
- Data access APIs vulnerable to brute-force attacks
- “Mirror” data servers that resemble development facilities, but are exposed in production with SSH access and labeled with names like “lab”
- Documentation ‘accidentally’ exposed, directing to a honeypot
- Data science Python library exposed on the server
- External access granted to a specific library
- Models imported as-is from GitHub
Monitoring and incident response are standard elements of security programs and AI can be included in it by understanding the relevant AI security assets, threats, and controls. The discussion of threats include detection mechanisms that become part of monitoring.
Note that new regulation can be more outcome-based (e.g. the EU AI Act), instead of control-focused (like ISO/IEC 27001) which makes it important to extend the Information Security Management System with assurance processes for showing that risks have been sufficiently mitigated.
References
Useful standards include:
The entire ISO 27000-27005 range is applicable to AI systems in the general sense as they are IT systems. Gap: covers this control fully regarding the processes, with the high-level particularity that there are three AI-specific attack surfaces that need to be taken into account in information security management: 1)AI development-time attacks including supply chain, 2)Input attacks, and 3)Runtime conventional security attacks. See the controls under the corresponding sections to see more particularities. These standards cover:
- ISO/IEC 27000 – Information security management systems – Overview and vocabulary
- ISO/IEC 27001 – Information security management systems – Requirements
- ISO/IEC 27002 – Code of practice for information security management (See below)
- ISO/IEC 27003 – Information security management systems: Implementation Guidelines
- ISO/IEC 27004 – Information security management measurements
- ISO/IEC 27005 – Information security risk management
The ‘27002 controls’ mentioned throughout this document are listed in the Annex of ISO 27001, and further detailed with practices in ISO 27002. At the high abstraction level, the most relevant ISO 27002 controls are:
- ISO 27002 control 5.1 Policies for information security
- ISO 27002 control 5.10 Acceptable use of information and other associated assets
- ISO 27002 control 5.8 Information security in project management
Risk analysis standards:
- This document contains AI security threats and controls to facilitate risk analysis
- See also MITRE ATLAS framework for AI threats
- ISO/IEC 27005 - as mentioned above. Gap: covers this control fully, with said particularity (as ISO 27005 doesn’t mention AI-specific threats)
- ISO/IEC 27563:2023 (AI use cases security & privacy) Discusses the impact of security and privacy in AI use cases and may serve as useful input to AI security risk analysis. The work bases its list of AI use cases on the 132 use cases belonging to 22 application domains in ISO/IEC TR 24030:2021, identifies 11 use cases with a maximum concern rating for security and 49 use cases with a maximum concern rating for privacy.
- ISO/IEC 23894 (AI Risk management). Gap: covers this control fully - It refers to ISO/IEC 24028 (AI trustworthiness) for AI security threats. However, ISO/IEC 24028 is not as comprehensive as AI Exchange (this document) or MITRE ATLAS as it is focused on risk management rather than threat enumeration.
- ISO/IEC 5338 (AI lifecycle) covers the AI risk management process. Gap: same as ISO 23894 above.
- ETSI Method and pro forma for Threat, Vulnerability, Risk Analysis
- NIST AI Risk Management Framework
- OpenCRE on security risk analysis
- NIST SP 800-53 on general security/privacy controls
- NIST cybersecurity framework
- GenAI security project LLM and GenAI Security Center of Excellence guide
#SEC DEV PROGRAM
Category: governance control
Permalink: https://owaspai.org/go/secdevprogram/
Description
Secure development program: Have processes concerning software development in place to make sure that security is built into your AI system.
Objective
Reduces security risks by proper attention to mitigating those risks during software development.
Implementation
The best way to do this is to build on your existing secure software development practices and include AI teams and AI particularities. This means that data science development activities should become part of your secure software development practices. Examples of these practices: secure development training, code review, security requirements, secure coding guidelines, threat modeling (including AI-specific threats), static analysis tooling, dynamic analysis tooling, and penetration testing. There is no need for an isolated secure development framework for AI.
Particularity
Particularities for AI in software development, and how to address them:
AI involves new types of engineering: data engineering and model engineering (e.g. model training), together with new types of engineers: e.g. data scientists, data engineers, AI engineers. Make sure this new engineering becomes an integral part of the general Development program with its best practices (e.g. versioning, portfolio management, retirement). For example: Version management/traceability of the combination of code, configuration, training data and models, for troubleshooting and rollback
New assets, threats and controls (as covered in this document) need to be considered, affecting requirements, policies, coding guidelines, training, tooling, testing practices and more. Usually, this is done by adding these elements in the organization’s Information Security Management System, as described in SECPROGRAM, and align secure software development to that - just like it has been aligned on the conventional assets, threats and controls (see SECDEVPROGRAM). This involves both conventional security threats and AI-specific threats, applying both conventional security controls and AI-specific ones. Typically, technical teams depend on the AI engineers when it comes to the AI-specific controls as they mostly require deep AI expertise. For example: if training data is confidential and collected in a distributed way, then a federated learning approach may be considered.
Apart from software components, the supply chain for AI can also include data and models which may have been poisoned, which is why data provenance and model management are central in AI supply chain management.
In AI, software components can also run in the development, for example tools to prepare training data or train a model. Because of this, the AI development environment is vulnerable to traditional software security risks, such as open source package vulnerabilities, CWEs, exposed secrets, and sensitive data leaks. Without robust controls in place, these risks go undetected by standard application security testing tools, potentially exposing the entire lifecycle to breaches.
The AI development environment typically involves sensitive data, in contrast to conventional engineering where the use of such data by engineers is normally avoided. Therefore, apply development security on the development environment. In addition to the conventional assets of code, configuration and secrets, the AI-specific development assets are:
- Potentially sensitive data needed to train, test and validate models
- Model parameters, which often represent intellectual property and can also be used to prepare input attacks when obtained.
New best practices or pitfalls in AI-specific code:
- Run static analysis rules specific to big data/AI technology (e.g., the typical mistake of creating a new dataframe in Python without assigning it to a new one)
- Run maintainability analysis on code, as data and model engineering code is typically hindered by code quality issues
- Evaluate code for the percentage of code for automated testing. Industry average is 43% (SIG benchmark report 2023). An often cited recommendation is 80%. Research shows that automated testing in AI engineering is often neglected (SIG benchmark report 2023), as the performance of the AI model is mistakenly regarded as the ground truth of correctness.
Model performance testing is essential
- Run AI-specific dynamic performance tests before deployment (see #CONTINUOUS VALIDATION):
- Run security tests (e.g. data poisoning payloads, prompt injection payloads, adversarial robustness testing). See the testing section.
- Run continual automated validation of the model, including discrimination bias measurement and the detection of staleness: the input space changing over time, causing the training set to get out of date
Model deployment is a new aspect to AI and it may offer specific protection measures such as obfuscation, encryption, integrity checks or a Trusted Execution Environment.
Risk-Reduction guidance
Depending on risk analysis, certain threats may require specific practices in the development lifecycle. These threats and controls are covered elsewhere in this document.
References
Useful standards include:
- ISO 27002 control 8.25 Secure development lifecycle. Gap: covers this control fully, with said particularity, but lack of detail - the 8.25 Control description in ISO 27002:2022 is one page, whereas secure software development is a large and complex topic - see below for further references
- ISO/IEC 27115 (Cybersecurity evaluation of complex systems)
- See OpenCRE on secure software development processes with notable links to NIST SSDF and OWASP SAMM. Gap: covers this control fully, with said particularity
#DEV PROGRAM
Category: governance control
Permalink: https://owaspai.org/go/devprogram/
Description
Development program: Having a development lifecycle program for AI. Apply general (not just security-oriented) software engineering best practices to AI development.
Data scientists are focused on creating working models, not on creating future-proof software per se. Often, organizations already have software practices and processes in place. It is important to extend these to AI development, instead of treating AI as something that requires a separate approach. Do not isolate AI engineering. This includes automated testing, code quality, documentation, and versioning. ISO/IEC 5338 explains how to make these practices work for AI.
Objective
This way, AI systems will become easier to maintain, transferable, secure, more reliable, and future-proof.
Implementation
A best practice is to mix data scientist profiles with software engineering profiles in teams, as software engineers typically need to learn more about data science, and data scientists generally need to learn more about creating future-proof, maintainable, and easily testable code.
Another best practice is to continuously measure quality aspects of data science code (maintainability, test code coverage), and provide coaching to data scientists in how to manage those quality levels.
Apart from conventional software best practices, there are important AI-specific engineering practices, including for example data provenance & lineage, model traceability and AI-specific testing such as continuous validation, testing for model staleness and concept drift. ISO/IEC 5338 discusses these AI engineering practices.
Related controls that are key parts of the development lifecycle:
The below interpretation diagram of ISO/IEC 5338 provides a good overview to get an idea of the topics involved.
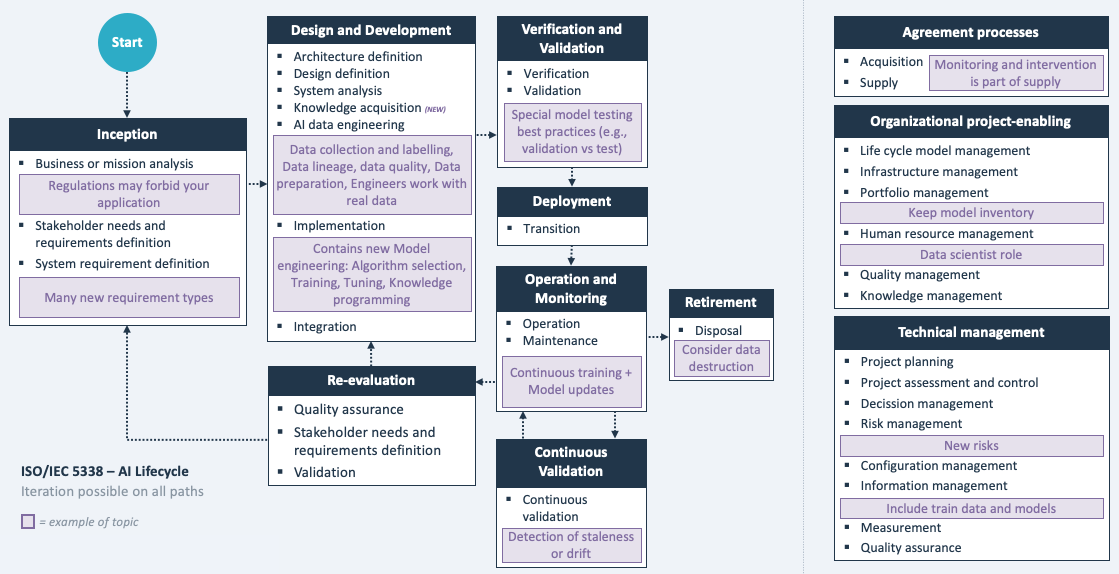
References
Useful standards include:
- ISO/IEC 5338 - AI lifecycle Gap: covers this control fully - ISO 5338 covers the complete software development lifecycle for AI, by extending the existing ISO 12207 standard on software lifecycle: defining several new processes and discussing AI-specific particularities for existing processes. See also this blog.
- ISO/IEC 27002 control 5.37 Documented operating procedures. Gap: covers this control minimally - this covers only a very small part of the control
- OpenCRE on documentation of function Gap: covers this control minimally
#CHECK COMPLIANCE
Category: governance control
Permalink: https://owaspai.org/go/checkcompliance/
Description
Check compliance: Make sure that AI-relevant laws and regulations are taken into account in compliance management (including security aspects). If personal data is involved and/or AI is applied to make decisions about individuals, then privacy laws and regulations are also in scope. See the Privacy section for details.
Objective
Compliance as a goal can be a powerful driver for organizations to grow their readiness for AI. While doing this, it is important to keep in mind that legislation has a scope that does not necessarily include all the relevant risks for the organization. Many rules are about the potential harm to individuals and society, and don’t cover the impact on business stakes per se. For example: the European AI act does not include risks for protecting company secrets. In other words: be mindful of blind spots when using laws and regulations as your guide.
Global Jurisdictional considerations (as of end of 2023):
- Canada: Artificial Intelligence & Data Act
- USA: (i) Federal AI Disclosure Act, (ii) Federal Algorithmic Accountability Act
- Brazil: AI Regulatory Framework
- India: Digital India Act
- Europe: (i) AI Act, (ii) AI Liability Directive, (iii) Product Liability Directive
- China: (i) Regulations on the Administration of Deep Synthesis of Internet Information Services, (ii) Shanghai Municipal Regulations on Promoting Development of AI Industry, (iii) Shenzhen Special Economic Zone AI Industry Promotion Regulations, (iv) Provisional Administrative Measures for Generative AI Services
Implementation
General Legal Considerations on AI/Security:
- Privacy Laws: AI must comply with all local/global privacy laws at all times, such as GDPR, CCPA, HIPAA. See the Privacy section.
- Data Governance: any AI components/functions provided by a 3rd party for integration must have data governance frameworks, including those for the protection of personal data and structure/definitions on how its collected, processed, stored
- Data Breaches: any 3rd party supplier must answer as to how they store their data and security frameworks around it, which may include personal data or IP of end-users
Non-Security Compliance Considerations:
- Ethics: Deep fake weaponization and how the system addresses and deals with it, protects against it and mitigates it
- Human Control: any and all AI systems should be deployed with appropriate levels of human control and oversight, based on ascertained risks to individuals. AI systems should be designed and utilized with the concept that the use of AI respects dignity and rights of individuals; “Keep the human in the loop” concept. See Oversight.
- Discrimination: a process must be included to review datasets to avoid and prevent any bias. See Unwanted bias testing.
- Transparency: ensure transparency in the AI system deployment, usage and proactive compliance with regulatory requirements; “Trust by Design”
- Accountability: AI systems should be accountable for actions and outputs and usage of data sets. See AI Program
References
- OpenCRE: AI compliance management referring to:
Useful standards include:
- OpenCRE on Compliance
- ISO 27002 Control 5.36 Compliance with policies, rules and standards. Gap: covers this control fully, with the particularity that AI regulation needs to be taken into account.
- ISO/IEC 27090 (AI security) and 27091 (AI privacy) are both in development at the moment of writing (Oct 2025), and likely come out in 2026. The AI Exchange has contributed substantial content to the 27090.
- prEN 18282 is the European standard for AI Security - brought forward by CEN/CENELEC and with a substantial part contributed by the AI Exchange. Exchange founder Rob van der Veer is liaison officer for the official partnership between the AI Exchange and CEN/CENELEC/ISO, as well as co-editor for 18282. The standard has been in development for almost two years at the moment of writing (Oct 2025) and expected to go into public enquiry early 2026, and be published in 2026.
#SEC EDUCATE
Category: governance control
Permalink: https://owaspai.org/go/seceducate/
Description
Education on AI security is a key prerequisite for AI engineers, development teams, and security professionals. The section on how to organize AI Security presents the following steps to understand AI security:
- Based on the inventory of your applications of AI and AI ideas, understand which threats apply
- Then make sure engineers and security professionals understand those relevant threats and their controls. Note that most of these controls are familiar conventional security countermeasures, unless you are training your own model.
- Use the courses and resources in the references section to support the understanding.
- Distinguish between controls that your organization has to implement, and those that are the responsibility of your supplier.
References
- OpenCRE: AI security Education referring to:
Useful standards include:
- ISO 27002 Control 6.3 Awareness training. Gap: covers this control fully, but lacks detail and needs to take into account the particularity: training material needs to cover AI security threats and controls
1.2 General controls for sensitive data limitation
Category: group of controls
Permalink: https://owaspai.org/go/datalimit/
The impact of security threats on confidentiality and integrity can be reduced by limiting the data attack surface, meaning that the amount and the variety of data is reduced as much as possible, as well as the duration in which it is kept. This section describes several controls to apply this limitation.
#DATA MINIMIZE
Category: development-time and runtime control
Permalink: https://owaspai.org/go/dataminimize/
Description
Data minimize: remove data fields or records (e.g. from a training set) that are unnecessary for the application, in order to prevent potential data leaks or manipulation because we cannot leak what isn’t there in the first place
Objective
Minimize the impact of data leakage or manipulation by reducing the amount of data processed by the system.
Applicability
Data minimization applies during data collection, preparation, training, evaluation, and runtime logging. It is particularly relevant when datasets contain personal, confidential, or exposure-restricted information.
An exception to applicability to the AI system provider is when the deployer is better positioned to implement (part of) this control, as long as the provider communicates this requirement to the deployer.
Implementation
In addition to removing (or archiving) unused or low-impact fields and records, data minimization can include:
- removing data elements (fields, record) that do not materially affect model performance (e.g. correctness, robustness, fairness) based on experimentation or analysis;
- retaining certain identifiers only to support data removal requests or lifecycle management, while excluding them from model training;
- updating training datasets to reflect removals or corrections made in upstream source data (e.g. when personal data is destroyed from the source data then training data is updated to reflect the change);
- original data can be preserved separately with access controls for future use.
Risk-Reduction Guidance
Data minimization reduces confidentiality risk by limiting the presence of exposure-restricted information. Data that is not collected or retained cannot be leaked, reconstructed, or inferred from the system. It also reduces the consequences of dataset theft or unauthorized access.
Particularity
AI models often tolerate reduced feature sets and incomplete data better than traditional applications, enabling stronger minimization strategies without functional loss.
References
- OpenCRE: Data minimization referring to:
Useful standards include:
- Not covered yet in ISO/IEC standards.
#ALLOWED DATA
Category: development-time and runtime control
Permalink: https://owaspai.org/go/alloweddata/
Description
Ensure allowed data, meaning: removing data (e.g. from a training set) that is prohibited for the intended purpose. This is particularly important if consent was not given and the data contains personal information collected for a different purpose.
Objective
Apart from compliance, the purpose is to minimize the impact of data leakage or manipulation
References
Useful standards include:
- ISO/IEC 23894 (AI risk management) covers this in A.8 Privacy. Gap: covers this control fully, with a brief section on the idea
#SHORT RETAIN
Category: development-time and runtime control
Permalink: https://owaspai.org/go/shortretain/
Description
Short retain: Remove or anonymize data once it is no longer needed, or when legally required (e.g., due to privacy laws).
Objective
Minimize the impact of data leakage or manipulation
Implementation
Limiting the retention period of data can be seen as a special form of data minimization. Privacy regulations typically require personal data to be removed when it is no longer needed for the purpose for which it was collected. Sometimes exceptions need to be made because of other rules (e.g. to keep a record of proof). Apart from these regulations, it is a general best practice to remove any sensitive data when it is no longer of use, to reduce the impact of a data leak.
References
Useful standards include:
- Not covered yet in ISO/IEC standards.
#OBFUSCATE TRAINING DATA
Category: development-time AI engineer control
Permalink: https://owaspai.org/go/obfuscatetrainingdata/
Description
Obfuscate training data: attain a degree of obfuscation of sensitive data where possible.
Objective
Minimize the impact of data leakage or manipulation when sensitive data cannot be removed entirely, by making the data less recognizable or harder to reconstruct.
Applicability
Data obfuscation is particularly relevant when exposure-restricted data is necessary for training, compliance, or risk mitigation, and cannot be removed.
An exception to applicability to the AI system provider is when the deployer is better positioned to implement this control, as long as the provider communicates this requirement to the deployer.
Implementation
Obfuscation techniques include:
Private Aggregation of Teacher Ensembles (PATE)
Private Aggregation of Teacher Ensembles (PATE) is a privacy-preserving machine learning technique. This method tackles the challenge of training models on sensitive data while maintaining privacy. It achieves this by employing an ensemble of “teacher” models along with a “student” model. Each teacher model is independently trained on distinct subsets of sensitive data, ensuring that there is no overlap in the training data between any pair of teachers. Since no single model sees the entire dataset, it reduces the risk of exposing sensitive information. Once the teacher models are trained, they are used to make predictions. When a new (unseen) data point is presented, each teacher model gives its prediction. These predictions are then aggregated to reach a consensus. This consensus is considered more reliable and less prone to individual biases or overfitting to their respective training subsets. To further enhance privacy, noise is added to the aggregated predictions. By adding noise, the method ensures that the final output doesn’t reveal specifics about the training data of any individual teacher model. The student model is trained not on the original sensitive data, but on the aggregated and noised predictions of the teacher models. Essentially, the student learns from the collective wisdom and privacy-preserving outputs of the teachers. This way, the student model can make accurate predictions without ever directly accessing the sensitive data. However, there are challenges in balancing the amount of noise (for privacy) and the accuracy of the student model. Too much noise can degrade the performance of the student model, while too little might compromise privacy.Objective function perturbation Objective function perturbation is a differential privacy technique used to train machine learning models while maintaining data privacy. It involves the intentional introduction of a controlled amount of noise into the learning algorithm’s objective function, which is a measure of the discrepancy between a model’s predictions and the actual results. The perturbation, or slight modification, involves adding noise to the objective function, resulting in a final model that doesn’t exactly fit the original data, thereby preserving privacy. The added noise is typically calibrated to the objective function’s sensitivity to individual data points and the desired privacy level, as quantified by parameters like epsilon in differential privacy. This ensures that the trained model doesn’t reveal sensitive information about any individual data point in the training dataset. The main challenge in objective function perturbation is balancing data privacy with the accuracy of the resulting model. Increasing the noise enhances privacy but can degrade the model’s accuracy. The goal is to strike an optimal balance where the model remains useful while individual data points stay private.
Masking
Masking involves the alteration or replacement of sensitive features within datasets with alternative representations that retain the essential information required for training while obscuring sensitive details. Various methods can be employed for masking, including tokenization, perturbation, generalization, and feature engineering. Tokenization replaces sensitive text data with unique identifiers, while perturbation adds random noise to numerical data to obscure individual values. Generalization involves grouping individuals into broader categories, and feature engineering creates derived features that convey relevant information without revealing sensitive details. Once the sensitive features are masked or transformed, machine learning models can be trained on the modified dataset, ensuring that they learn useful patterns without exposing sensitive information about individuals. However, achieving a balance between preserving privacy and maintaining model utility is crucial, as more aggressive masking techniques may lead to reduced model performance.Encryption
Encryption is a fundamental technique for pseudonymization and data protection. It underscores the need for careful implementation of encryption techniques, particularly asymmetric encryption, to achieve robust pseudonymization. Emphasis is placed on the importance of employing randomized encryption schemes, such as Paillier and Elgamal, to ensure unpredictable pseudonyms. Furthermore, homomorphic encryption, which allows computations on ciphertexts without the decryption key, presents potential advantages for cryptographic operations but poses challenges in pseudonymization. The use of asymmetric encryption for outsourcing pseudonymization and the introduction of cryptographic primitives like ring signatures and group pseudonyms in advanced pseudonymization schemes are important.
There are two models of encryption in machine learning:- (part of) the data remains in encrypted form for the data scientists all the time, and is only in its original form for a separate group of data engineers that prepare and then encrypt the data for the data scientists.
- The data is stored and communicated in encrypted form to protect against access from users outside the data scientists, but is used in its original form when analysed, and transformed by the data scientists and the model. In the second model it is important to combine the encryption with proper access control, because it hardly offers protection to encrypt data in a database and then allow any user access to that data through the database application.
Tokenization
Tokenization is a technique for obfuscating data with the aim of enhancing privacy and security in the training of machine learning models. The objective is to introduce a level of obfuscation to sensitive data, thereby reducing the risk of exposing individual details while maintaining the data’s utility for model training. In the process of tokenization, sensitive information, such as words or numerical values, is replaced with unique tokens or identifiers. This substitution makes it difficult for unauthorized users to derive meaningful information from the tokenized data.
Within the realm of personal data protection, tokenization aligns with the principles of differential privacy. When applied to personal information, this technique ensures that individual records remain indiscernible within the training data, thus safeguarding privacy. Differential privacy involves introducing controlled noise or perturbations to the data to prevent the extraction of specific details about any individual.
Tokenization aligns with this concept by replacing personal details with tokens, increasing the difficulty of linking specific records back to individuals. Tokenization proves particularly advantageous in development-time data science when handling sensitive datasets. It enhances security by enabling data scientists to work with valuable information without compromising individual privacy. The implementation of tokenization techniques supports the broader objective of obfuscating training data, striking a balance between leveraging valuable data insights and safeguarding the privacy of individuals.
Risk-Reduction Guidance
Obfuscation reduces the likelihood that training data can be reconstructed or linked back to individuals. Effectiveness can be evaluated through attack testing or by relying on formal privacy guarantees such as differential privacy or an equivalent mathematical framework. Residual risk remains when exposure-restricted data is still present, when obfuscation mechanisms fail, or when reconstruction or re-identification remains possible, such as through access to token mapping tables.
Particularity
AI models typically do not require exact or human-readable representations of training data, allowing obfuscation techniques that would be impractical in traditional systems. In traditional systems, data attributes are processed directly leaving less room for obfuscation techniques.
Limitations
Obfuscation reduces the risk of re-identification or inference, but does not eliminate it:
- Removing or obfuscating PII / personal data is often not sufficient, as someone’s identity may be induced from the other data that you keep of the person (locations, times, visited websites, activities together with data and time, etc.).
- Token-based approaches introduce additional risk if mapping tables are compromised.
The risk of re-identification can be assessed by experts using statistical properties such as K-anonymity, L-diversity, and T-closeness.
Anonymity is not an absolute concept, but a statistical one. Even if someone’s identity can be guessed from data with some certainty, it can be harmful. The concept of differential privacy helps to analyse the level of anonymity. It is a framework for formalizing privacy in statistical and data analysis, ensuring that the privacy of individual data entries in a database is protected. The key idea is to make it possible to learn about the population as a whole while providing strong guarantees that the presence or absence of any single individual in the dataset does not significantly affect the outcome of any analysis. This is often achieved by adding a controlled amount of random noise to the results of queries on the database. This noise is carefully calibrated to mask the contribution of individual data points, which means that the output of a data analysis (or query) should be essentially the same, whether any individual’s data is included in the dataset or not. In other words by observing the output, one should not be able to infer whether any specific individual’s data was used in the computation.
Distorting training data can make it effectively unrecognizable, which of course needs to be weighed against the negative effect on model performance that this typically creates. See also TRAINDATADISTORTION which is about distortion against data poisoning and EVASIONROBUSTMODEL for distortion against evasion attacks. Together with this control OBFUSCATETRAININGDATA, these are all approaches that distort training data, but for different purposes.
References
- OpenCRE: Training data obfuscation referring to:
- SF-PATE: Scalable, Fair, and Private Aggregation of Teacher Ensembles
- Differentially Private Objective Perturbation: Beyond Smoothness and Convexity
- Data Masking with Privacy Guarantees
- Abadi, M., Chu, A., Goodfellow, I., McMahan, H. B., Mironov, I., Talwar, K., & Zhang, L. (2016). Deep learning with differential privacy. Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, 308-318. Link
- Dwork, C., & Roth, A. (2014). The Algorithmic Foundations of Differential Privacy. Foundations and Trends in Theoretical Computer Science. Link
Useful standards include:
- Not covered yet in ISO/IEC standards.
#DISCRETE
Category: development-time and runtime control
Permalink: https://owaspai.org/go/discrete/
Description
Minimize access to technical details that could help attackers.
Objective
Reduce the information available to attackers, which can assist them in selecting and tailoring their attacks, thereby lowering the probability of a successful attack.
Implementation
Minimizing and protecting technical details can be achieved by incorporating such details as an asset into information security management. This will ensure proper asset management, data classification, awareness education, policy, and inclusion in risk analysis.
Note: this control needs to be weighed against the #AI TRANSPARENCY control that may require to be more open about technical aspects of the model. The key is to minimize information that can help attackers while being transparent.
For example:
- Consider this risk when publishing technical articles on the AI system
- When choosing a model type or model implementation, take into account that there is an advantage of having technology with which attackers are less familiar
- Minimize technical details in model output
References
- OpenCRE: Protection of technical AI information referring to:
Useful standards include:
- ISO 27002 Control 5.9: Inventory of information and other associated assets. Gap: covers this control fully, with the particularity that technical data science details can be sensitive. .
- See OpenCRE on data classification and handling. Gap: idem
- MITRE ATlAS Acquire Public ML Artifacts
1.3. Controls to limit the effects of unwanted behaviour
Category: group of controls
Permalink: https://owaspai.org/go/limitunwanted/
Unwanted model behaviour is the intended result of many AI attacks (e.g. data poisoning, evasion, prompt injection). There are many ways to prevent and to detect these attacks, but this section is about how the effects of unwanted model behaviour can be controlled, in order to reduce the impact of an attack - by constraining actions, introducing oversight and enabling timely containment and recovery. This is sometimes referred to as blast radius control.
Besides attacks, AI systems can display unwanted behaviour for other reasons, making the control of this behaviour a shared responsibility, beyond just security. Key causes of unwanted model behaviour include:
- Insufficient or incorrect training data
- Model staleness/ Model drift (i.e. the model becoming outdated)
- Mistakes during model and data engineering
- Feedback loops where model output ends up in the training data of future models, which leads to model collapse (also known as recursive pollution)
- Security threats: attacks as laid out in this document
Successfully mitigating unwanted model behaviour has its own threats:
- Overreliance: the model is being trusted too much by users
- Excessive agency: the model is being trusted too much by engineers and gets excessive functionality, permissions, or autonomy
Example: When Large Language Models (GenAI) can perform actions, the privileges around which actions and when become important (OWASP for LLM 07).
Example: LLMs (GenAI), just like most AI models, induce their results based on training data, meaning that they can make up things that are false. In addition, the training data can contain false or outdated information. At the same time, LLMs (GenAI) can come across as very confident about their output. These aspects make overreliance of LLM (GenAI) (OWASP for LLM 09) a real risk, plus excessive agency as a result of that (OWASP for LLM 08). Note that all AI models in principle can suffer from overreliance - not just Large Language Models.
Controls to limit the effects of unwanted model behaviour:
- #OVERSIGHT
- #LEAST MODEL PRIVILEGE
- #MODEL ALIGNMENT
- #AI TRANSPARENCY
- #CONTINUOUS VALIDATION
- #EXPLAINABILITY
- #UNWANTED BIAS TESTING
#OVERSIGHT
Category: runtime control
Permalink: https://owaspai.org/go/oversight/
Description
Oversight of model behaviour by humans or automated mechanisms (e.g.,using rules), where human oversight provides not only more intelligent validation through common sense and domain knowledge, but also clear accountability for divisions and outcomes.
Objective
Detect unwanted model behavior and respond to it. Responses include correcting, halting execution, deferring to an (other) human-in-the-loop, or issuing an alert to be investigated.
Applicability
It is the nature of AI models that they can be wrong. In addition, they can be manipulated (e.g., prompt injection, data poisoning, evasion), so it is critical to apply a layer of protection that oversees the output of the model. It is the final checkpoint.
Implementation
- Implement detection rules to recognize (potential) unwanted output, such as:
- Offensive language, toxicity, Not Safe For Work, misinformation, or dangerous information (e.g., recipe for poison, medical misinformation)
- Sensitive data: see SENSITIVE OUTPUT HANDLING for the control to detect sensitive data (e.g. names, phone numbers, passwords, tokens). These detections can also be applied on the input of the model or on APIs that retrieve data to go into the model.
- A special category of sensitive data: system prompts, as they can be used by attackers to circumvent prompt injection protection in such prompts.
- Suspicious function calls. Ideally, the privileges of an AI model are already hardened to the task (see #LEAST MODEL PRIVILEGE), in which case detection comes down to issuing an alert once a model attempts to execute an action for which it has no permissions. In addition, the strategy can include the detection of unusual function calls in the context, issuing alerts for further investigation, or asking for approval by a human in the loop. Manipulation of function flow is commonly referred to as application flow perturbation. An advanced way to detect manipulated workflows is to perform rule-based sanity checks during steps, e.g. verify whether certain safety checks of filters were executed before processing data.
- Apply Grounding checks if recognizing unwanted output based on context is too difficult to catch in rules, and the detection of malicious input is insufficient. The idea of grounding checks is to let a separate Generative AI model decide if an input or output is off-topic or escalates capabilities (e.g. a LLM powered food recipes app suddenly is trying to send emails). This takes the use of LLMs to detect suspicious input and output a step further by including context. This is required in case GenAI-based recognition is insufficient to cover certain attack scenarios (see above).
- Implement appropriate general detection and response mechanisms as presented in #MONITOR USE where part of the response can be to involve a human-in-the-loop.
- Include as part of response options rollback mechanisms to enable oversight to go back to a certain state after system malfunction or manipulation has been observed and the state of the system cannot be trusted, or has been disrupted.
- For checks that require accountability and/or more expertise and common sense, present the behaviour for a human to approve. This can be the result of a logic rule that in specific circumstances escalates to a human-in-the-loop.
- Ensure that the human oversight is appropriate: the human is qualified, instructed, motivated, and not suffering from so-called approval fatigue: the result of having to approve many actions that are mostly in order.
A separate form of oversight is MODEL ALIGNMENT which intends to constrain model behaviour through training, fine-tuning, and system prompts. This is treated as a separate control because the effectiveness is limited and therefore no guarantee.
Examples:
- Logic preventing the trunk of a car from opening while the car is moving, even if the driver seems to request it
- Logic signaling an alert when a software programming tool is making a series of updates to multiple projects in one go, after which the alert is processes by a human who can then decide to further investigate and/or to take action, which can include shutting down the complete system to prevent further harm
- Requesting user confirmation before sending a large number of emails as instructed by a model
- Another form of human oversight is allowing users to undo or revert actions initiated by the AI system, such as reversing changes made to a file
- A special form of guardrails is censoring unwanted output of GenAI models (e.g. violent, unethical)
Limitations
Limitations of automated oversight:
The properties of wanted or unwanted model behavior often cannot be entirely specified, limiting the effectiveness of guardrails.
Limitations of human oversight: The downsides of human oversight aare:
- More costly and slower
- The risk of ‘approval fatigue’ where humans are overwhelmed by approval requests, especially if the large majority of those are okay.
- Lack of expertise to judge
- Lack of involvement in the situation to make the judgement - which is a form of lack of expertis
Ad.4: Regarding lack of involvement: for human operators or drivers of automated systems like self-driving cars, staying actively involved or having a role in the control loop helps maintain situational awareness. This involvement can prevent complacency and ensures that the human operator is ready to take over control if the automated system fails or encounters a scenario it cannot handle. However, maintaining situational awareness can be challenging with high levels of automation due to the “out-of-the-loop” phenomenon, where the human operator may become disengaged from the task at hand, leading to slower response times or decreased effectiveness in managing unexpected situations. In other words: If you as a user are not involved actively in performing a task, then you lose understanding of whether it is correct or what the impact can be. If you then only need to confirm something by saying ‘go ahead’ or ‘cancel’, a badly informed ‘go ahead’ is easy to pick.
References
- OpenCRE: Automated AI oversight referring to:
- OpenCRE: Human AI oversight referring to:
Useful standards include:
- ISO/IEC 42001 B.9.3 defines controls for human oversight and decisions regarding autonomy. Gap: covers this control partly (human oversight only, not business logic)
- Not covered further in ISO/IEC standards.
#LEAST MODEL PRIVILEGE
Category: runtime information security control
Permalink: https://owaspai.org/go/leastmodelprivilege/
Description
Least model privilege: Minimize what a model can do (trigger actions or access data), to prevent harm in case the model is manipulated, or makes a mistake by itself.
Implementation
- Limit both permissions and attack surface. Privileges can be controlled by configuring permissions in an authorization mechanism, and by removing access to elements and thus reducing the attack surface for a manipulated model (e.g., isolating or sand-boxing an agent by removing commands it could call from an image, or limit network access).
- Honor limitations of the served: Execute actions of AI systems with the rights and privileges of the user or service being served. This ensures that no actions are invoked and no data is retrieved outside authorizations. Note that the served is always just the initiator of an action - for example if the initiator wants the AI system to provide information to others. In that case, the authorization of those others should also be taken into account.
- Task-based minimization: Take the served-limitation a step further by reducing actions that the model can potentially trigger, and what they can be triggered on, to the minimum necessary for the reasonably foreseeable use cases. See below for the flexibility balance here. The purpose of this is blast radius control: to limit the attack surface in case the AI model is compromised, or in case the AI model makes a mistake. This requires mechanisms that may not be offered by the Identity and Access Management in place, such as: ephemeral tokens, dynamic permissions, and narrow permission control at scale, combined with trust establishment and potential revocation across different domains. See ‘Strategies for task-based minimization’ below.
- Avoid implementing authorization in Generative AI instructions, as these are vulnerable to hallucinations and manipulation (e.g., prompt injection). This is especially applicable in Agentic AI. This includes the prevention of Generative AI outputting commands that include references to the user context as it would open up the opportunity to escalate privileges by manipulating that output.
Example case: an AI model is connected to an email facility to summarize incoming emails to an end user:
- Honor limitations of the actor: make sure the AI only can access the emails the end user can access. -Task-based minimization: limit the email access to read-only - with the goal to avoid the model being manipulated to for example send spam emails, or include misinformation in the summaries, or gain access to sensitive emails of the user and send those to the attacker.
Flexibility balance
How to strike the balance between:
- a general purpose AI agent that has all permissions which you can assign to anything, and
- a large set of AI agents, each for a different type of task with the right set of permissions to prevent it stepping out of bounds?
Option 1 is the easiest extreme and option 2 requires more effort and also may cause certain workflows to fail because the agent didn’t have permissions, causing user frustration and administrator effort to further tailor agents and permissions.
Still, least model privilege is critical if successful manipulation is probable and the potential effects are severe. The best practice is to at least have separate agents for the permissions that may have severe effects (e.g. execute run commands). This puts the responsibility of selecting the right permissions to the actor choosing the agent. This can introduce the risk of the actor (person or agent) choosing an agent with too many permissions because they are not sufficiently informed, or they prefer flexibility over security too much. If this risk is real, then dynamic minimization of permissions is required. This requires the implementation of logic that sets action permissions based on knowledge of the intent (e.g. an agent that is assigned to summarize a ticket only gets access to read tickets), and knowledge of potential risks (e.g. reducing permissions automatically the moment that untrusted input is introduced in an agent workflow).
One of the most powerful things to let AI agents do is to execute code. That is where task-based minimization becomes a challenge because on the one hand you want to broaden the possibilities for the agents, and on the other hand you want to limit those possibilities for attackers. Solutions include:
- Replacing arbitrary code execution with the execution of a limited set of API calls
- Removing commands (e.g. deleting them from a deployed operating system
- Sand boxing the code execution by for example network segmentation, to minimize the attack surface of commands
Strategies for task-based minimization
As mentioned above, it is essential to minimize actions that the model can potentially trigger, and what they can be triggered on. This needs to be minimized based on who or what is served (see above) and on the task. Strategies for task-based minimization include:
- Harden based on general intent: Since agents and agentic systems typically don’t have a single fixed task: at least minimize permissions based on the reasonably foreseeable use cases.
- Harden based on prompt intent: The original prompt to an agent contains intent. Mechanisms (typically LLM based) can interpret that and set permissions. This is where least privilege mechanisms start to overlap with what is presented under #OVERSIGHT, including grounding checks. The difference is that the least privilege mechanism uses preventative permissions and the oversight mechanism is reactive. The effect is the same, and the advantage of permissions can be that they may serve as permissions for any subagents, which allows for inheritance of the context in the agentic flow.
- Harden based on role assignment: As soon as an agent or agentic flow is assigned to a specific task (e.g., an LLM assigned to review new code in the form of a merge request), the permissions can be minimized to the role to perform that task.
- Harden based on risk elevation: Logic can be implemented to harden permissions the moment that certain input enters an agentic flow - from un untrusted agent, from an untrusted source (e.g., a public comment database), or the other way around: sensitive data entering the flow. From that moment, the logic can for example disable all actions that allow sending out sensitive data. This needs to be balanced of course with whether the intent is still possible, and whether the inclusion of those risk elevating elements is reason to downgrade agentic capability.
- Downgrading subagents: Have inter-agent calls include reduced permission sets, where possible.For example: an email handling agent calling another agent to summarize an email message. Such a hand-down mechanism is best performed outside the LLM because of reliability issues of the model. For example, LangChain supports this mechanism using tools and subagents. However, fine-grained runtime permission handoff (like delegated scoped credentials) is not native.
- Hardening as incident response: Based on the level of suspicion, automated or manual response mechanisms may harden an agentic flow, to reduce blast radius of a potentially corrupted state, without fully stopping it - so to limit interference of the response.
- Ephemeral permissions: if an assigned task is expected to be done in a certain amount of time, then certain permissions can be set as temporary, to prevent manipulated agents making use of these permissions to cause harm. This can be seen as temporal blast radius control.
- Informing and nudging users to harden agents: End users and administrators can have an important role in hardening permissions of agentic AI based on the task. Their general incentive is to NOT harden agents because 1) it takes time to analyse what is necessary, and 2) if the user is wrong, agentic tasks may fail. Therefore, it is important to create awareness with users about the risks and information on which permissions to set for which functions and which not to set for which risks. This is a form of #AI TRANSPARENCY. Strategies include: providing user training and user documentation on this subject, showing guidance in the user interface, with suggestions, and giving warnings in case riskful permissions are set.
References
- OpenCRE: Model action privilege minimization
referring to:
- MITRE ATLAS: sec. AML.M0028: AI Agent Tools Permissions Configuration
- MITRE ATLAS: sec. AML.M0026: Privileged AI Agent Permissions Configuration
- MITRE ATLAS: sec. AML.M0027: Single-User AI Agent Permissions Configuration
- ENISA: sec. Table 5:: Apply a RBAC model, respecting the least privileged principle
- ISO 27002 control 8.2 Privileged access rights. Gap: covers this control fully, with the particularity that privileges assigned to autonomous model decisions need to be assigned with the risk of unwanted model behaviour in mind.
- OpenCRE on least privilege Gap: idem
- A Novel Zero-Trust Identity Framework for Agentic AI: Decentralized Authentication and Fine-Grained Access Control
#MODEL ALIGNMENT
Category: development-time and runtime AI engineer control
Permalink: https://owaspai.org/go/modelalignment/
Description and objective
In the context of Generative AI (e.g., LLMs), alignment refers to the process of ensuring that the model’s behavior and outputs are consistent with human values, intentions, and ethical standards.
Controls external to the model to manage model behaviour are:
- OVERSIGHT: conventional mechanisms responding to the actual outcome of the model
- LEAST MODEL PRIVILEGE: conventional mechanisms that put boundaries on what the model can affect
- PROMPT INJECTION I/O handling: detection mechanisms on input and output to prevent unwanted behaviour
The intent of Model alignment is to achieve similar goals by baking it into the model itself, through training and instruction.
Implementation
Achieving the goal of model alignment involves multiple layers:
Training-Time Alignment: the maker of the model shaping its core behaviour
This is often what people mean by “model alignment” in the strict sense:
- Training data choices
- Fine-tuning (on aligned examples: helpful, harmless, honest)
- Reinforcement learning from human feedback (RLHF) or other reward modeling
Deployment-Time Alignment (Including System Prompts)
Even if the model is aligned during training, its actual behavior during use is also influenced by:
- System prompts / instruction prompts
- Guardrails built into the AI system and external tools that oversee or control responses (like content filters or output constraints) - see the external controls mentioned above
See the appendix on culture-sensitive alignment.
Limitations
Advantage of Model alignment over the external mechanisms:
- Training-time alignment is in essence able to capture complex behavioural boundaries in the form of many examples of wanted and less-wanted behaviour
- Recognition of unwanted behaviour is very flexible as the GenAI model typically has powerful judgement abilities.
Disadvantages of Model alignment:
- A model’s ability to behave through alignment suffers from reliability issues, as it can be prone to manipulation or imperfect memorization and application of what it has learned and what it has been told.
- The boundaries of unwanted model behaviour may change after model training (e.g., through new findings), forcing the use of system prompts and/or external controls
Therefore, alignment should be seen as a probabilistic, model-internal control that must be combined with deterministic, external mechanisms for high-risk or regulated use cases.
#AI TRANSPARENCY
Category: governance and runtime control
Permalink: https://owaspai.org/go/aitransparency/
Description
AI transparency: Informing users on the AI system’s properties to enable them to adjust how they rely on it, what data they are willing to send to it, and what additional mitigations to apply. These AI system properties can include:
- Rough working of the model
- The training approach
- Type of data used and the source
- Expected accuracy and robustness of the AI system’s output
- Any residual (security) risks
Note that transparency here is about providing abstract information regarding the AI system and is therefore something else than explainability of model decisions. The simplest form of transparencey is to inform users that an AI model is being involved. This is for example required by the EU AI Act for chatbots.
See the DISCRETE control for the balance between being transparent and being discrete about the model.
Example: Informing users that when they choose an agent to perform a task, that the agent could be manipulated if it reads untrusted data and what consequences that could have (residual security risk) - followed by a recommendation to configure the permissions of the agent to the minimal set for the task.
References
- ISO/IEC 42001 B.7.2 describes data management to support transparency. Gap: covers this control minimally, as it only covers the data management part.
- Not covered further in ISO/IEC standards.
- OWASP top 10 for LLM 09 on over-reliance
#CONTINUOUS VALIDATION
Category: development-time and runtime AI engineer control
Permalink: https://owaspai.org/go/continuousvalidation/
Description
Continuous validation: by frequently testing the behaviour of the model against an appropriate test set, it is possible to detect sudden changes caused by a permanent attack (e.g. data poisoning, model poisoning), and also some robustness issues against for example evasion attacks.
Continuous validation is a process that is often in place to detect other issues than attacks: system failures, or the model performance going down because of changes in the real world since it was trained (model drift, model staleness). There are many performance metrics available and the best ones are those that align with the goal. These metrics pertain to correctness, but can also link to other aspects such as unwanted bias towards protected attributes.
Note that continuous validation is typically not suitable for detecting backdoor poisoning attacks, as these are designed to trigger with very specific input that would normally not be present in test sets. In fact, such attacks are often designed to pass validation tests.
Objective
Continuous validation helps verify that the model continues to behave as intended over time meeting acceptance criteria. In addition to supporting functional correctness, it provides a mechanism to detect unexpected or unexplained changes in model behaviour that may indicate permanent manipulation, such as data poisoning or model poisoning. Continuous validation may also surface certain robustness weaknesses, including limited exposure to evasion-related failure modes.
In some systems, model behaviour directly implements security-relevant functions, such as access control or policy enforcement, making correctness validation important from a cybersecurity perspective.
Applicability
Continuous validation applies to AI systems where changes in model behaviour could introduce security, safety, or compliance risks. It is particularly relevant when risks related to data poisoning, model poisoning, or unintended behavioural drift are not fully acceptable.
Implementation
Implementation of timing and triggers
Continuous validation can be performed at points in the system lifecycle where model behaviour may reasonably change or be at risk of manipulation. This includes:
- after initial training, retraining, or fine-tuning,
- before deployment or redeployment, and
- periodically during operation when the residual risk of model integrity is not considered acceptable.
Operational validation is particularly relevant when models remain exposed to updates, external dependencies, or environments where unauthorized modification is plausible. The frequency and scope of validation are typically informed by risk analysis and the criticality of the model’s output.
Implementation of degradation detection and response handling
Validation results can be monitored for unexpected or unexplained changes in model performance, which may indicate permanent behavioural changes caused by attacks, configuration errors, or environmental drift.
When performance degradation or abnormal behaviour is observed, possible response options include:
- investigating the underlying cause;
- continuing operation when degradation is temporary and within acceptable bounds;
- rolling back to a previous model version with known behaviour;
- restricting usage to lower-risk scenarios or specific tasks;
- introducing additional human or automated oversight for high-risk outputs to limit error propagation; or
- temporarily disabling the system if continued operation is unsafe.
The choice of response influences both the impact of the issue and the timeliness of recovery.
Implementation of test data management and protection
Test datasets serve as a reference for intended or acceptable model behaviour and therefore benefit from protection against manipulation. Storing test data separately from training data or model artifacts can reduce the likelihood that attackers influence both the model and its evaluation baseline.
When test data remains less exposed than training data or deployed model components, continuous validation can help surface integrity issues even if other parts of the system are compromised.
Risk-Reduction Guidance
Continuous validation can be an effective mechanism for detecting permanent behavioural changes caused by attacks such as data poisoning or model poisoning. Detection timeliness depends on how frequently validation is performed and whether the manipulated model has already been deployed.
The level of impact from a detected degradation depends on both the severity of the behaviour change and the response taken. Responses may include investigation, rollback to a previous model version, restricting usage to lower-risk scenarios, or introducing additional oversight for high-risk outputs.
Continuous validation is not a strong countermeasure against evasion attacks and does not guarantee detection of attacks designed to bypass validation, such as trigger-based backdoor poisoning.
For poisoning introduced during development or training, validation before deployment can prevent exposure entirely, whereas poisoning introduced during operation may only be detected after some period of use, depending on validation frequency.
Particularity
There is a terminology difference between AI performance testing and traditional performance testing in non-AI systems. The latter focuses on efficiency metrics such as latency or throughput, whereas performance testing of AI models focuses on behavioural correctness, robustness, and consistency with intended use. It may also include checks for bias or unintended decision patterns.
Limitations
Continuous validation relies on the representativeness and integrity of the test dataset. Attacks that are triggered only by rare or highly specific inputs may not be detected if those inputs are absent from test sets.
If attackers are able to manipulate both the model and the test data, validation results may no longer be trustworthy. Validation alone therefore does not replace other integrity and monitoring controls.
References
- OpenCRE: AI model performance validation referring to:
Useful standards include:
- ISO 5338 (AI lifecycle) Continuous validation. Gap: covers this control fully
- ISO/IEC 24029-2:2023 Artificial intelligence (AI) — Assessment of the robustness of neural networks
- ISO/IEC 24027:2021 Bias in AI systems and datasets
- ISO/IEC 25059:2023 Software engineering — Systems and software Quality Requirements and Evaluation (SQuaRE) — Quality model for AI systems
- CEN/CLC JT021008 AI trustworthiness framework
#EXPLAINABILITY
Category: runtime AI engineer control
Permalink: https://owaspai.org/go/explainability/
Description
Explainability: Explaining how individual model decisions are made, a field referred to as Explainable AI (XAI), can aid in gaining user trust in the model. In some cases, this can also prevent overreliance, for example, when the user observes the simplicity of the ‘reasoning’ or even errors in that process. See this Stanford article on explainability and overreliance. Explanations of how a model works can also aid security assessors to evaluate AI security risks of a model.
#UNWANTED BIAS TESTING
Category: development-time and runtime AI engineer control
Permalink: https://owaspai.org/go/unwantedbiastesting/
Description
Unwanted bias testing: By doing test runs of the model to measure unwanted bias, unwanted behaviour caused by an attack can be detected. The details of bias detection fall outside the scope of this document as it is not a security concern - other than that, an attack on model behaviour can cause bias.
